视频
- 文本识别 OCR 神器 MMOCR【OpenMMLab】_哔哩哔哩_bilibili
- TommyZihao/MMOCR_tutorials: Jupyter notebook tutorials for MMOCR (github.com)
课程
1
文本识别 OCR 神器 MMOCR【OpenMMLab】

OpenMMLab 是一个开源人工智能算法体系,涵盖了多种领域的多种人工智能算法的开源实现。

open-mmlab/mmocr: OpenMMLab Text Detection, Recognition and Understanding Toolbox (github.com) 是 OpenMMLab 下的一个用于 OCR 领域的工具包。包含如下功能:
- 文本区域检测
- 文本内容识别
- 关键信息提取

课程所包含的代码实战教程。

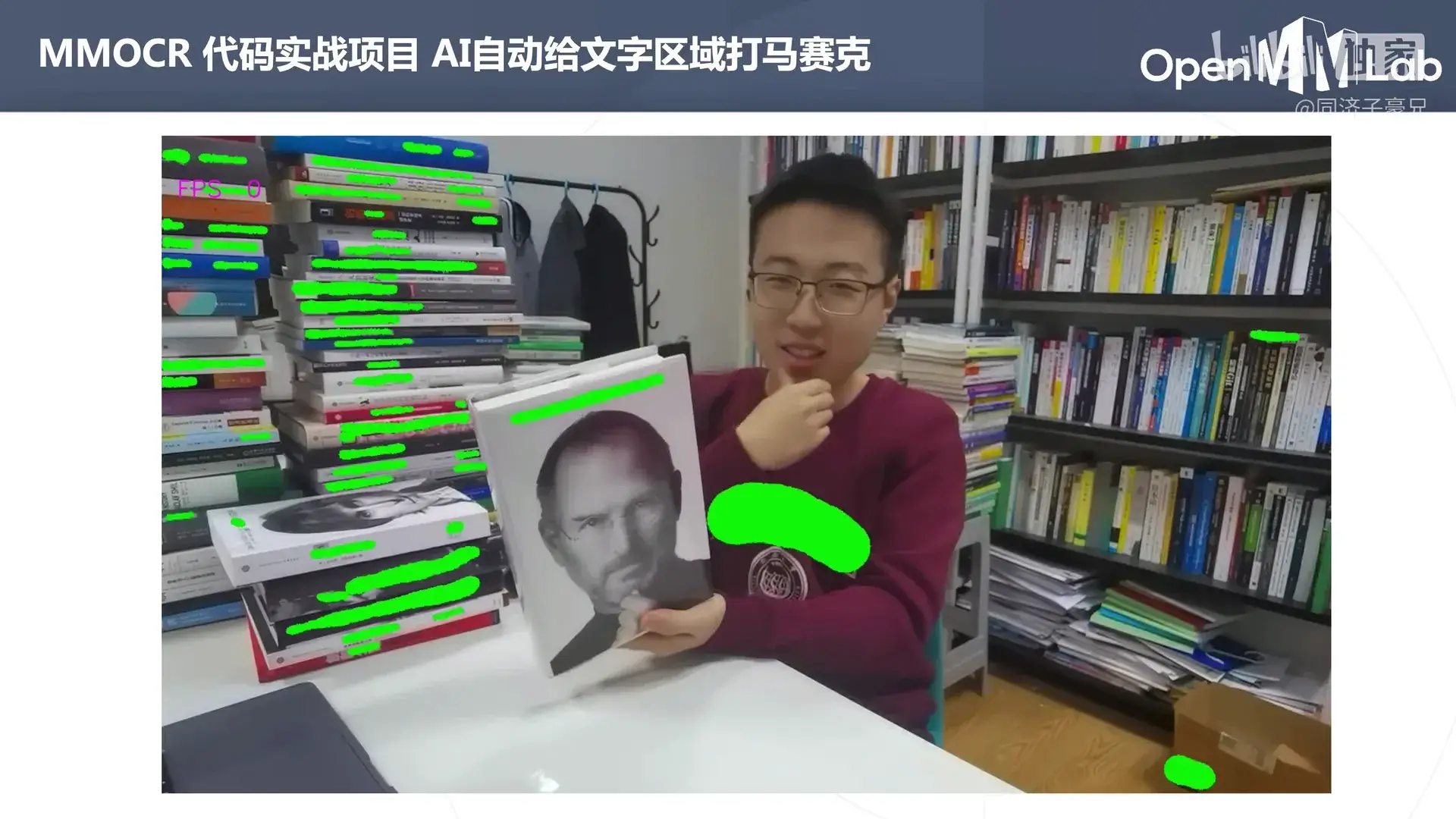
课程中将基于 TextSnake 给文字区域打马赛克。




OCR 即光学字符识别,包含文本区域检测、文本内容识别和关键信息提取。

对于文本识别,又分为文档文本识别和场景文本识别。

文本图像可能存在噪音、复杂背景、多语种、倾斜、弯曲、多形状和多种字体等属性,是 OCR 的难点与挑战。
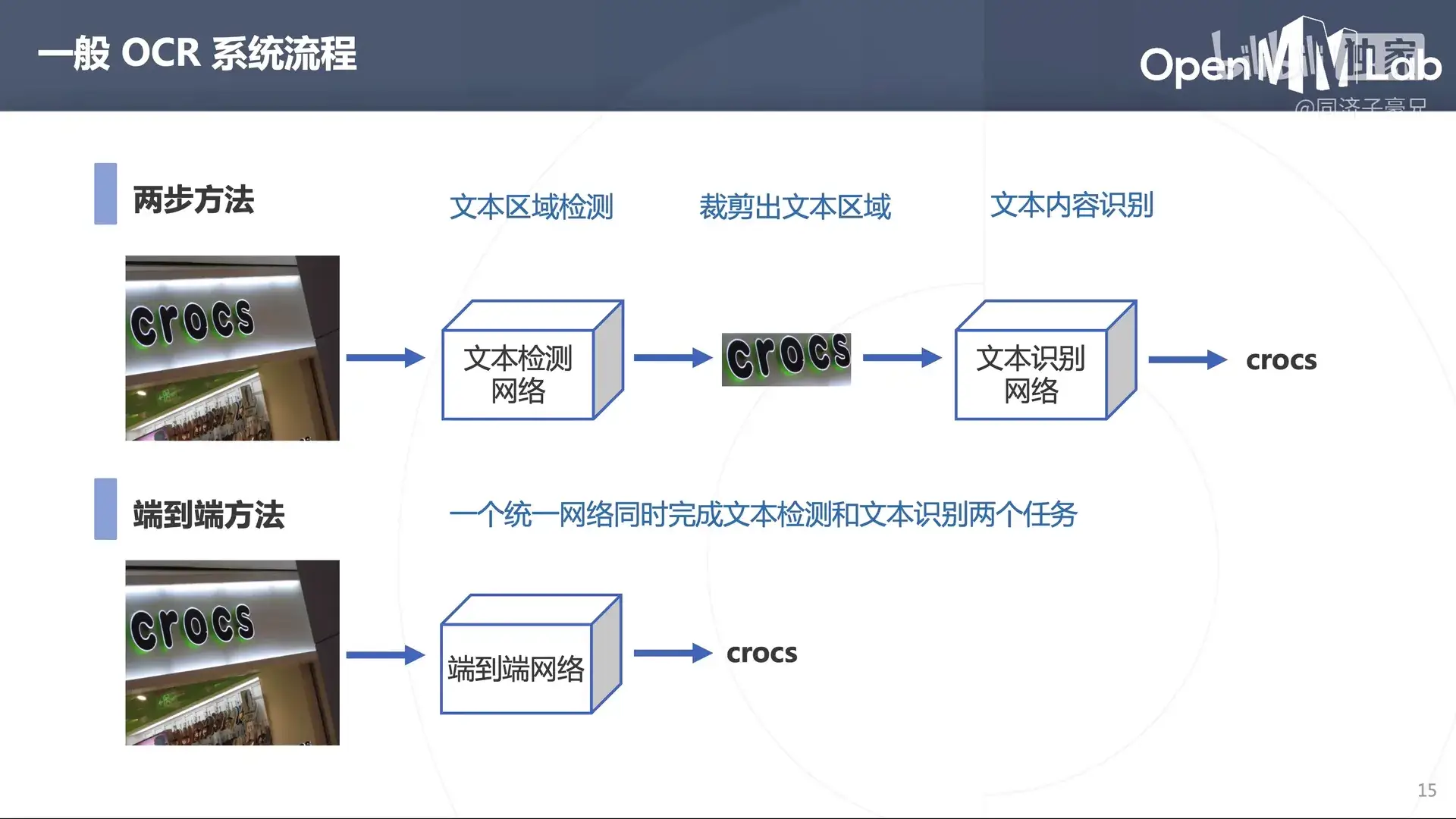
一般的 OCR 系统流程分为两种:
- 两部方法
- 文本区域检测-裁剪出文本区域-文本内容识别
- 端到端方法
- 一个统一网络同时完成文本检测和文本识别两个任务
学会 MMOCR 能做什么

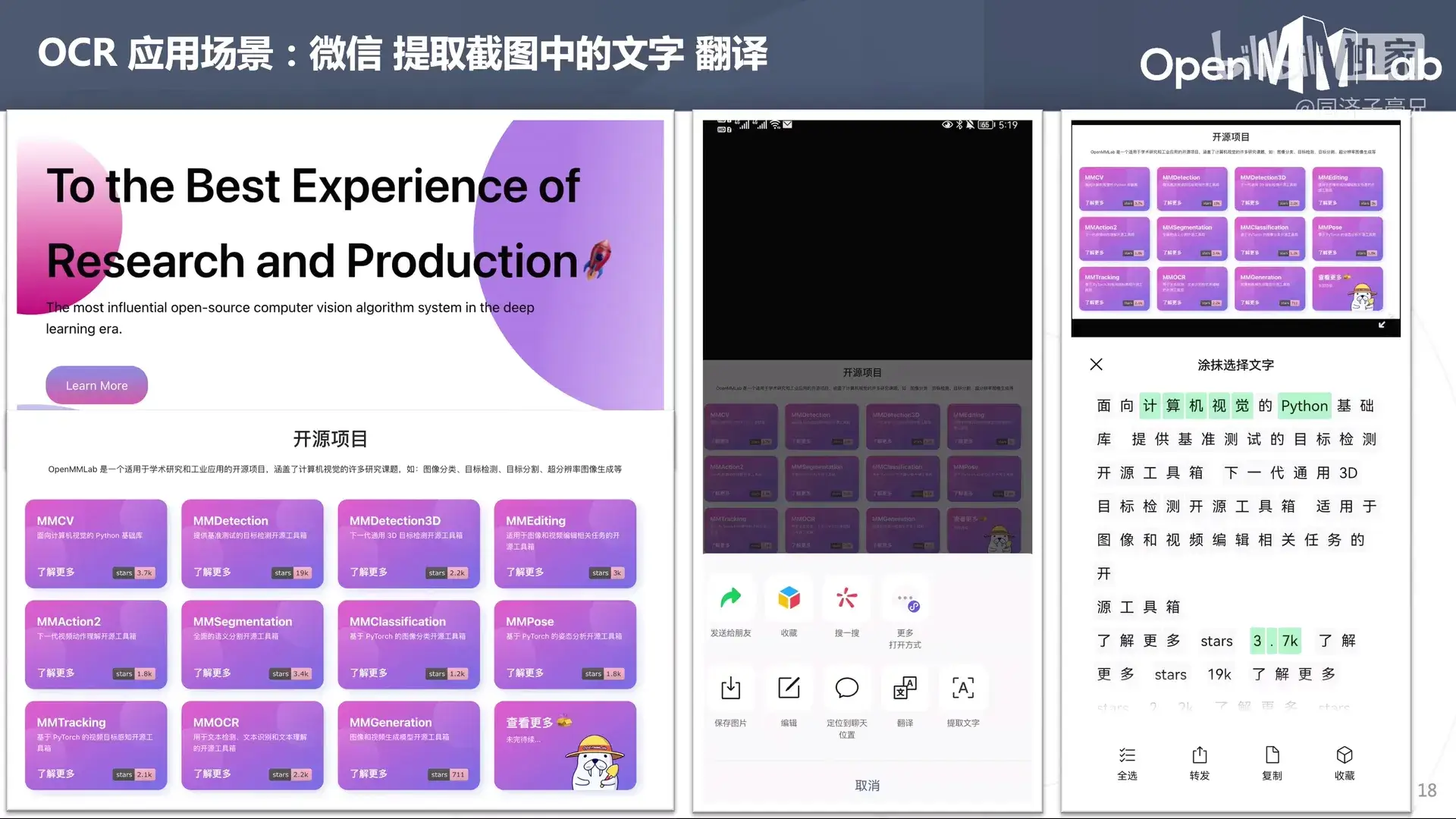
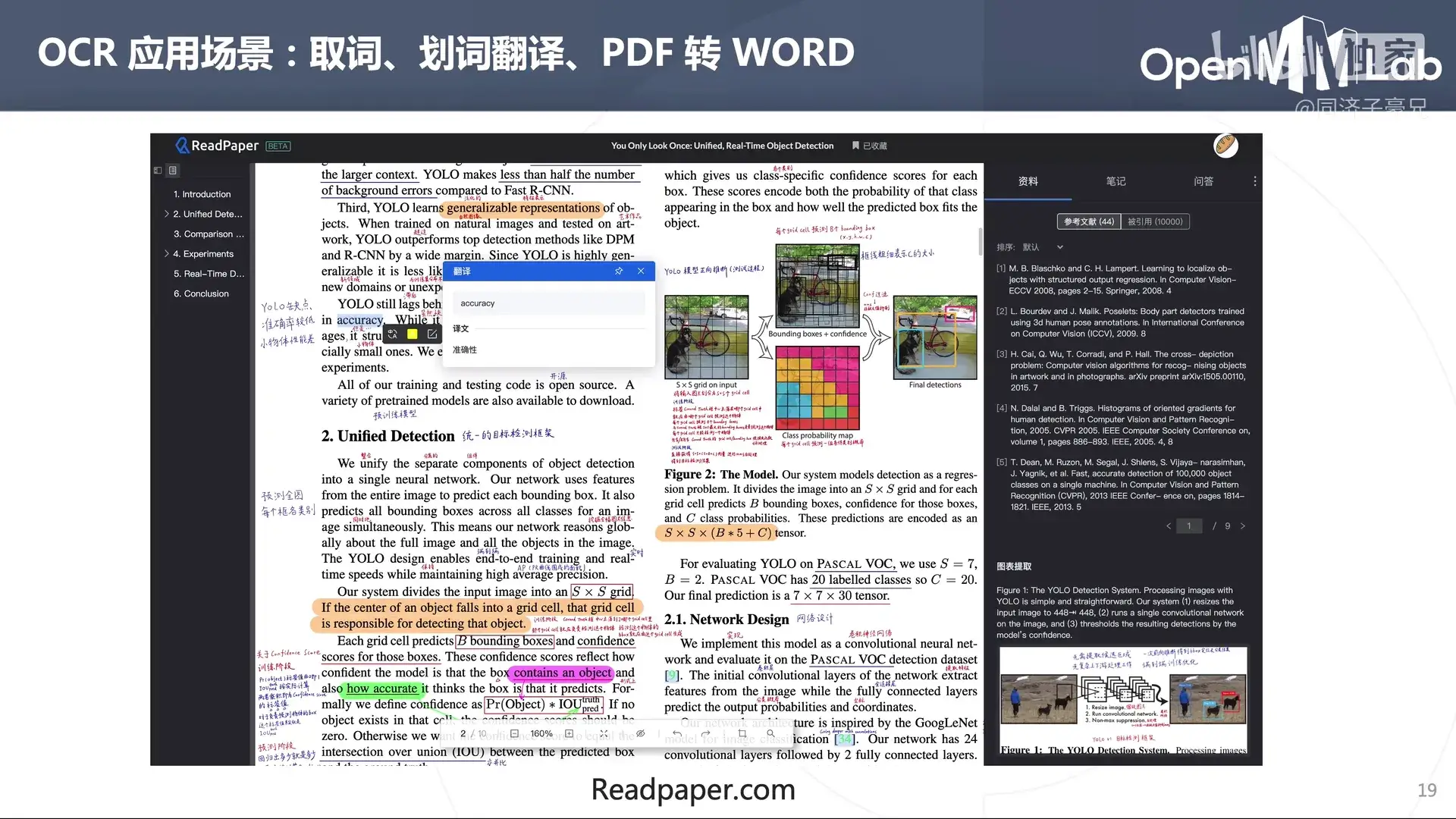
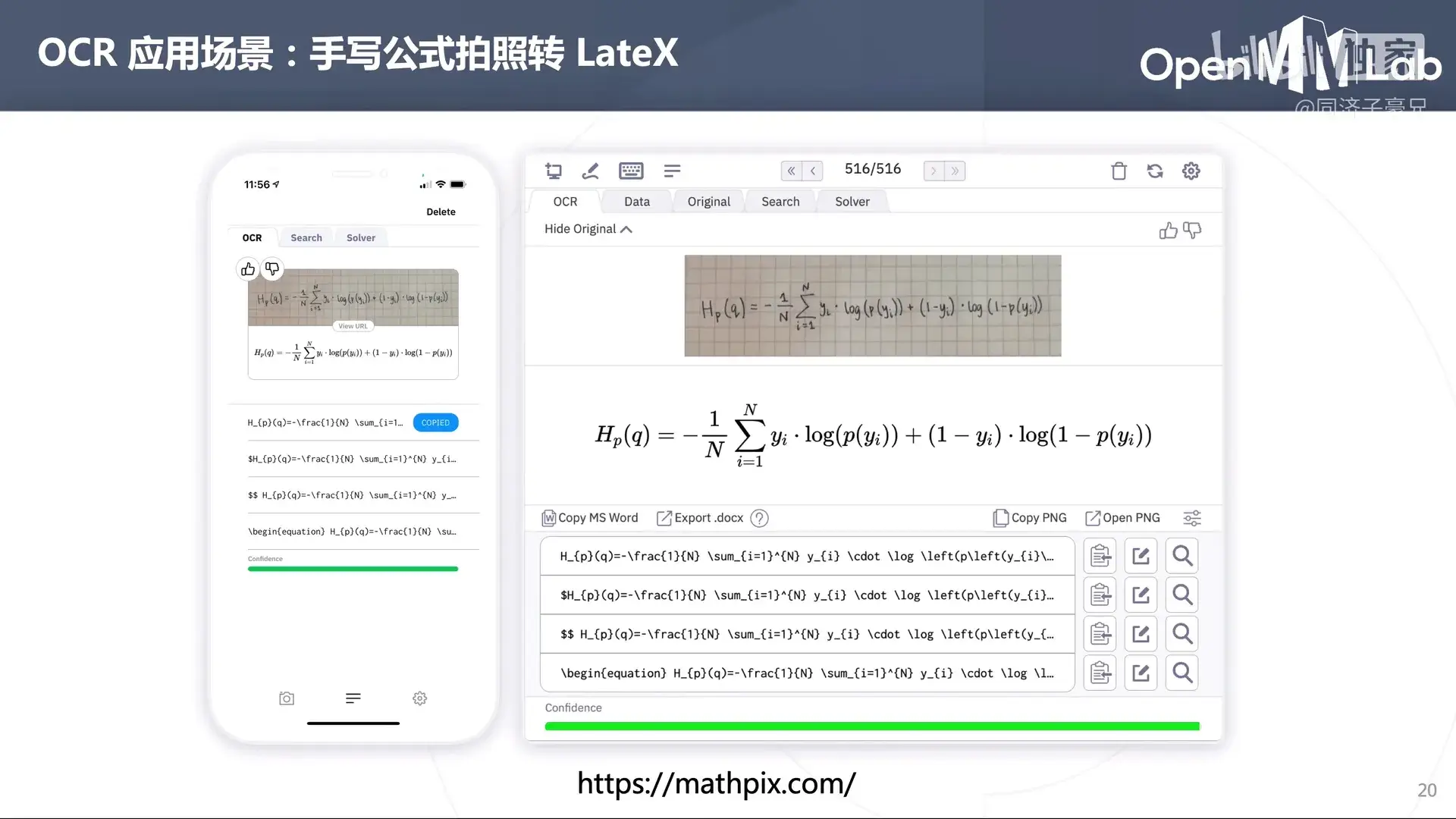
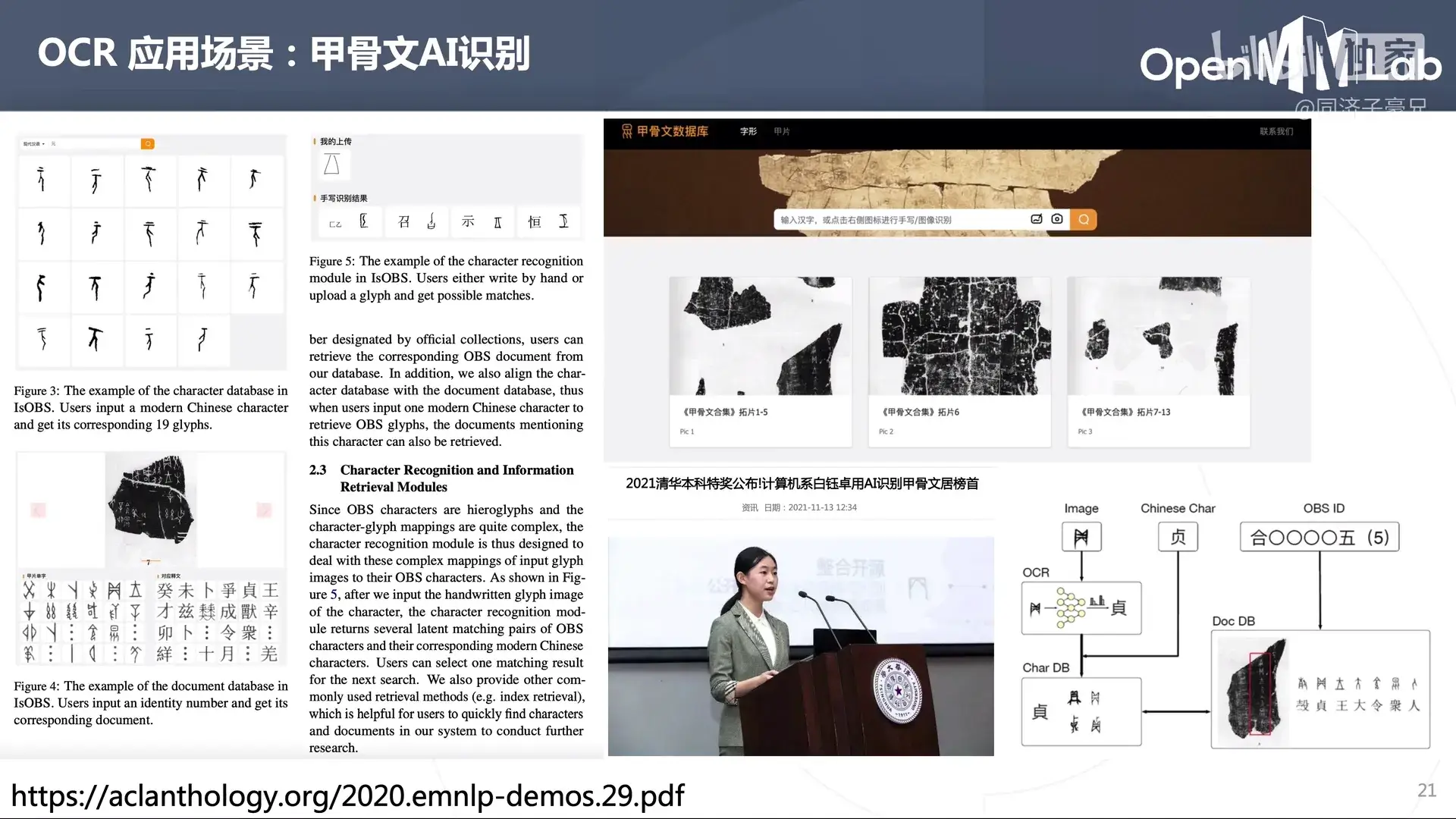
清华本科特奖的一个项目。


关键信息提取是 OCR 的下游任务之一。
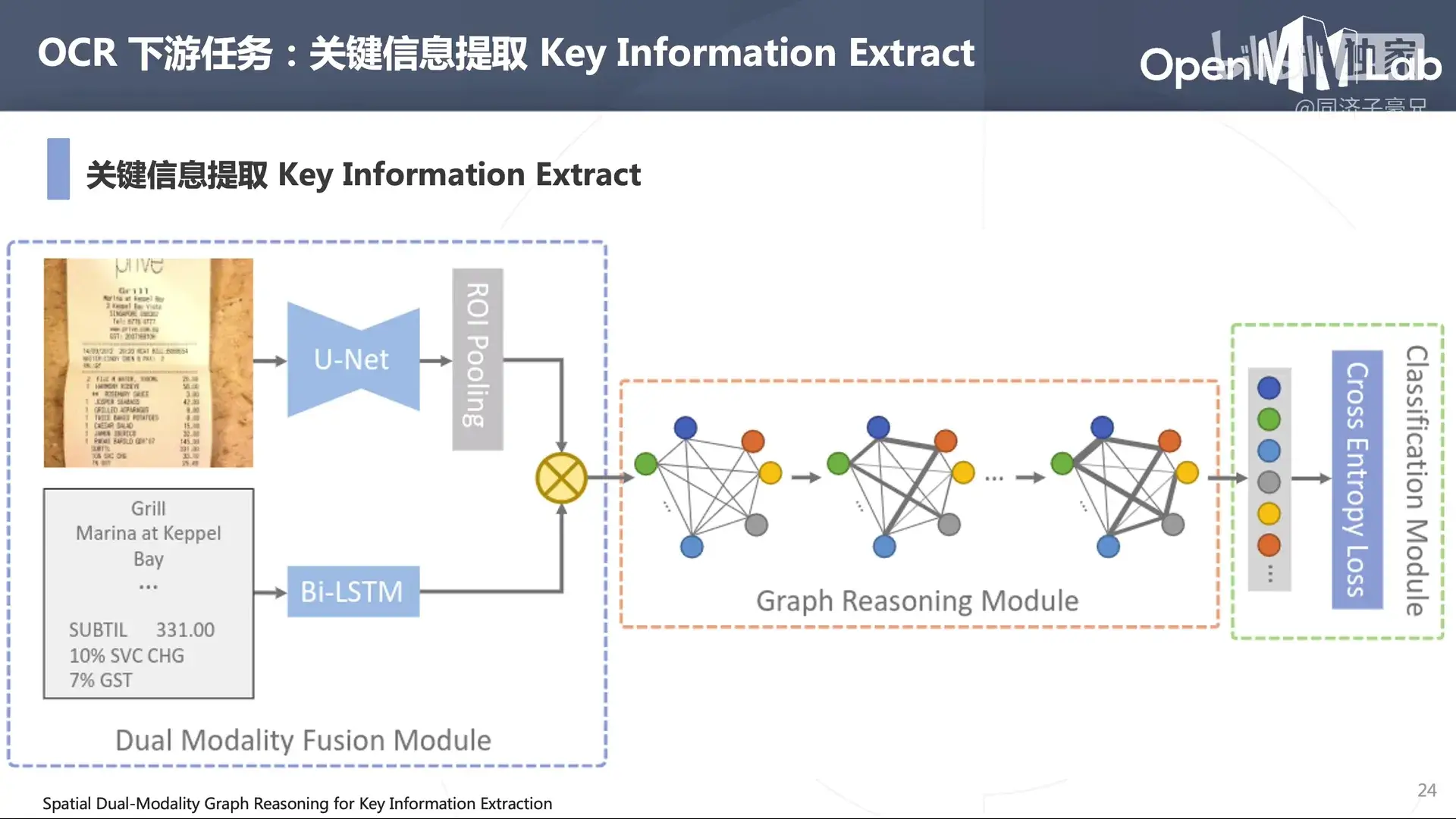

开源 OCR 算法库:MMOCR
上述下游任务的实现有些需要调用第三方 API,如果我们想使用自己的数据集进行训练、无限量地使用等,开源的 OCR 算法库是一个好的解决方案。
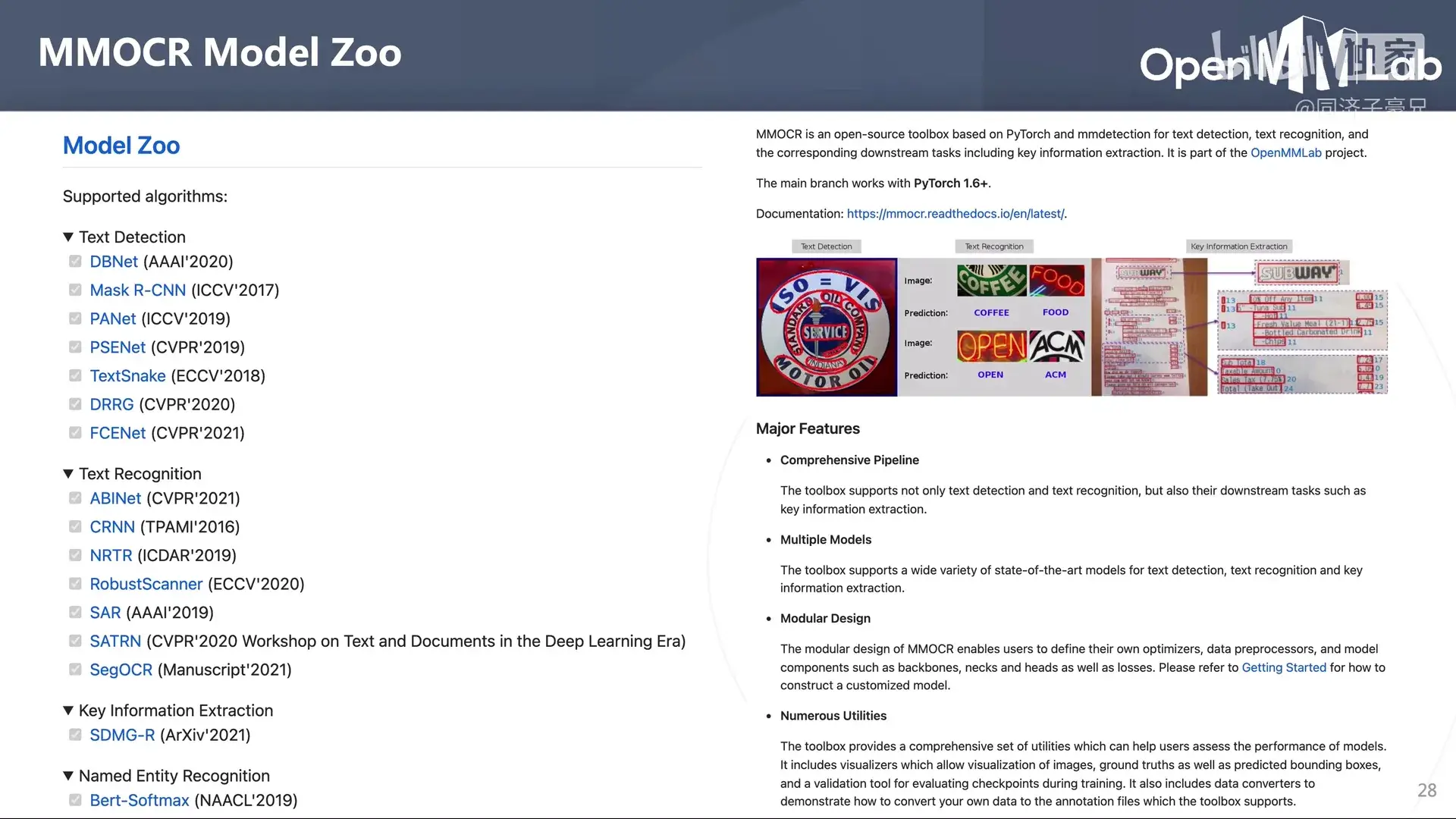
MMOCR 集成了若干顶会所提出的前沿算法。

各种算法的简介和使用方法可以在官方文档中找到。

MMOCR 所包含的文本区域检测算法:
- MaskRCNN
- PAN
- PSENet
- DB
- TextSnake
- DRRG
- FCENet

MMOCR 所包含的文本内容识别算法:
- CRNN
- Robust
- Scanner
- SAR
- SegOCR
- Transformer
- ABINet
- SATRN
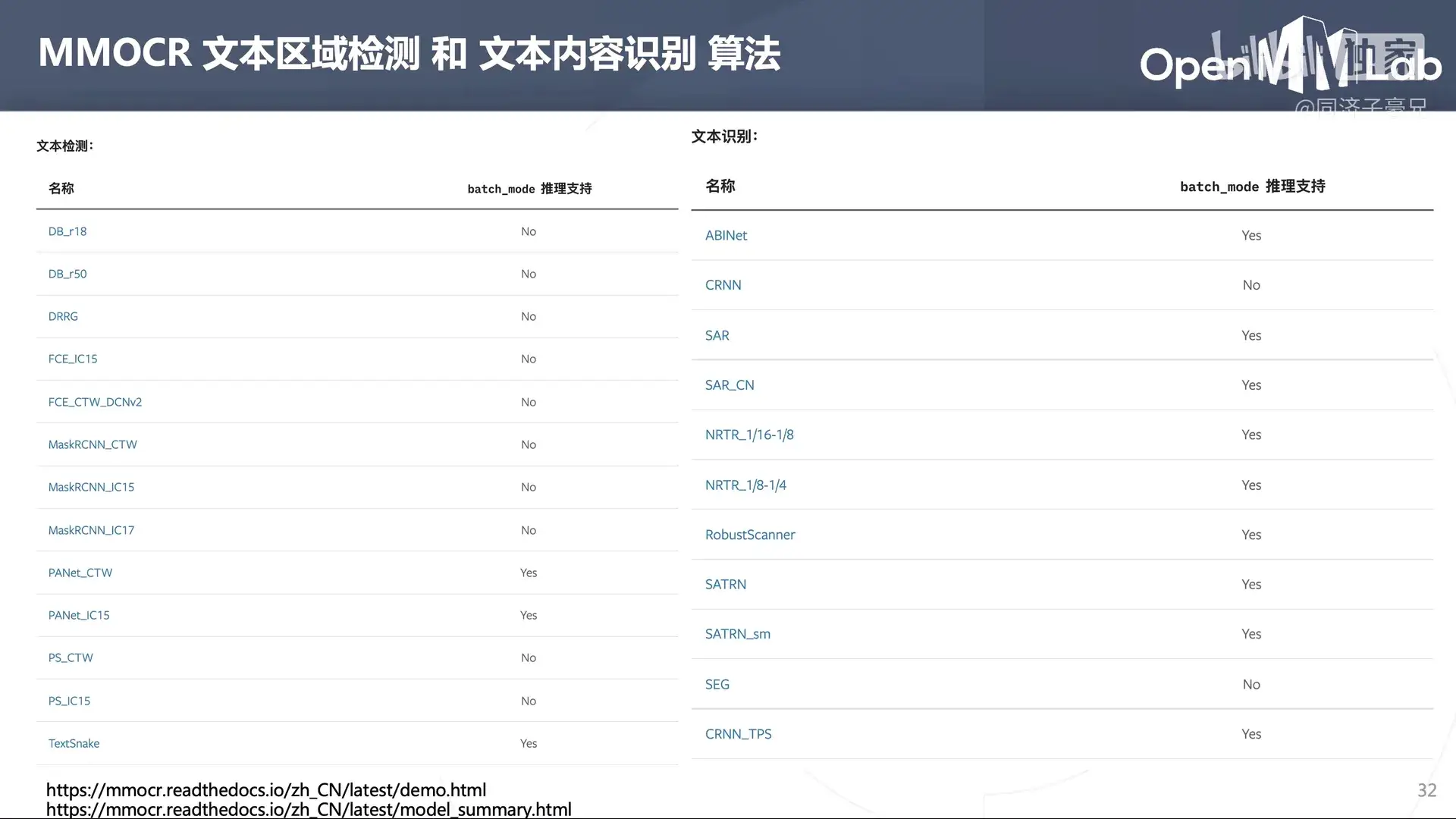

MMOCR 包含的 OCR 下游任务——Text Understanding 文本内容理解算法:
- Key Information Extraction: SDMG-R 关键信息提取
- Named Entity Recognition: Bert-softmax 命名实体识别
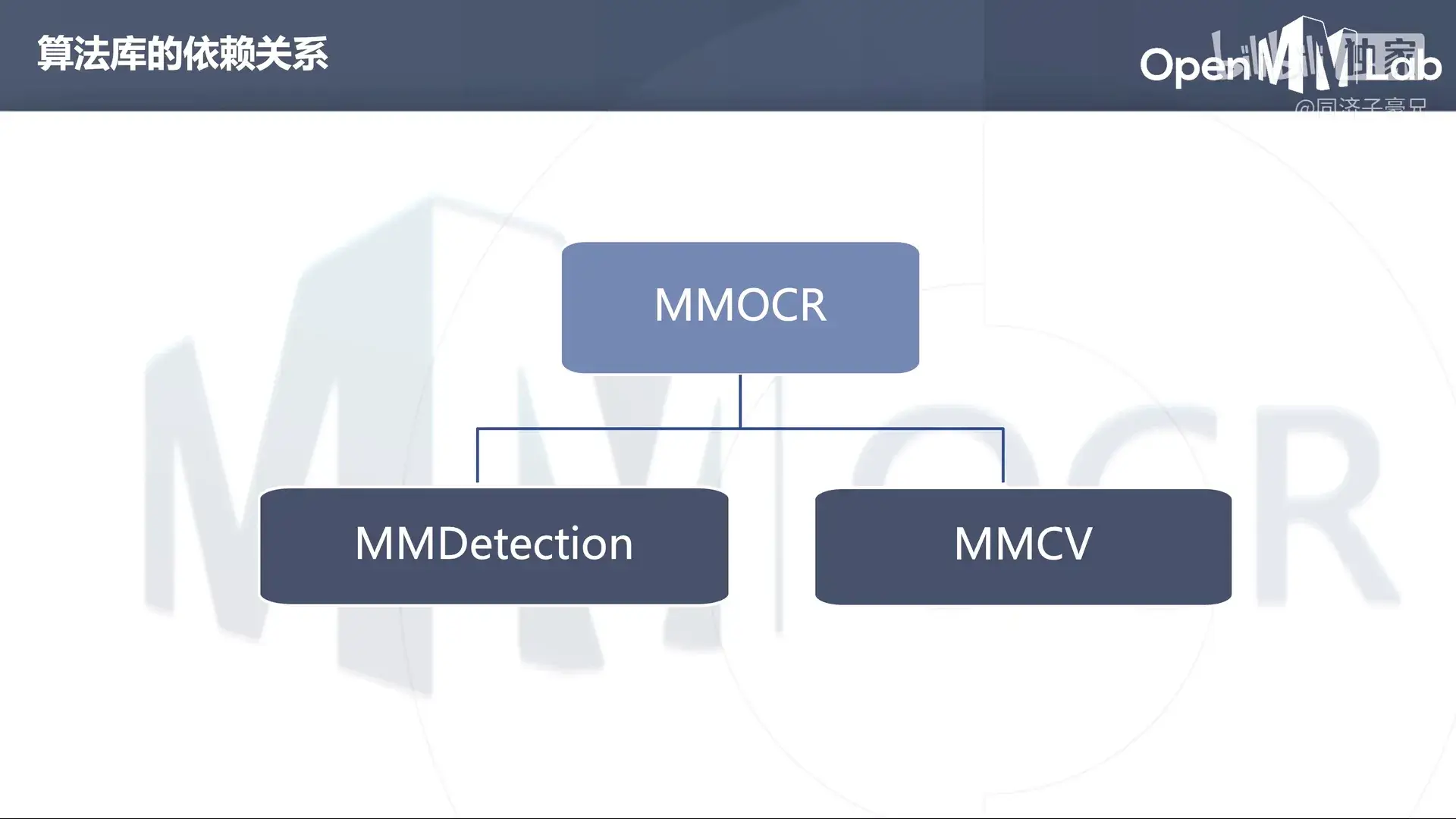
MMOCR 依赖于 MMDetection 和 MMCV。
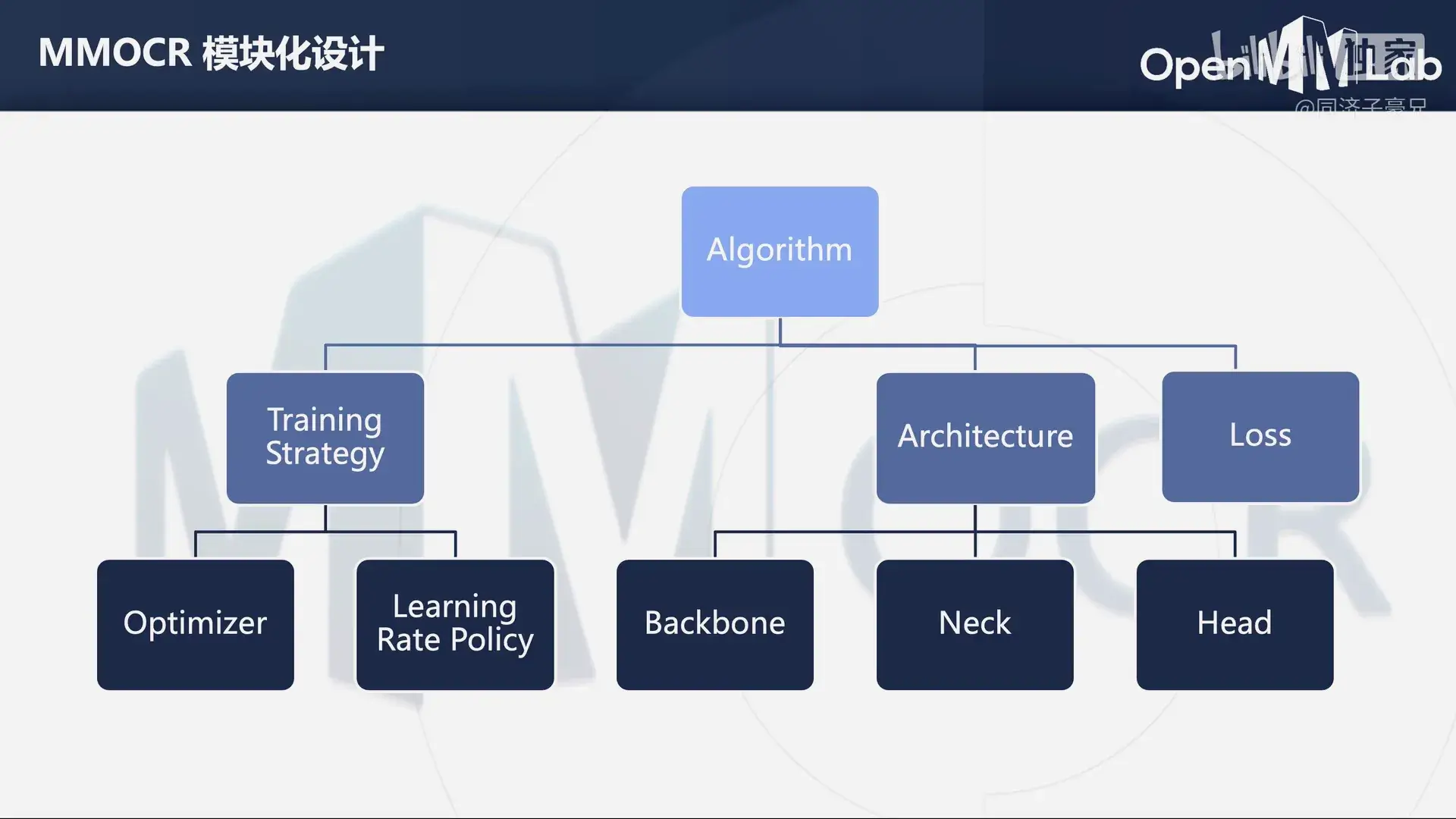
MMOCR 具有模块化设计。

MMOCR 所包含的功能:
- 数据集
- 常用 OCR 数据集及格式转换工具
- 训练
- 单机训练
- 多机训练
- 集群训练
- Slurm 调度器
- 测试
- 主流性能评估指标
- FLOPS 评估
- 速度评估
- 可视化
- 文本检测
- 文本识别
- 关键信息提取
- 部署(便于部署到实际应用中)
- 导出为 ONNX
- ONNX 转 TensorRT
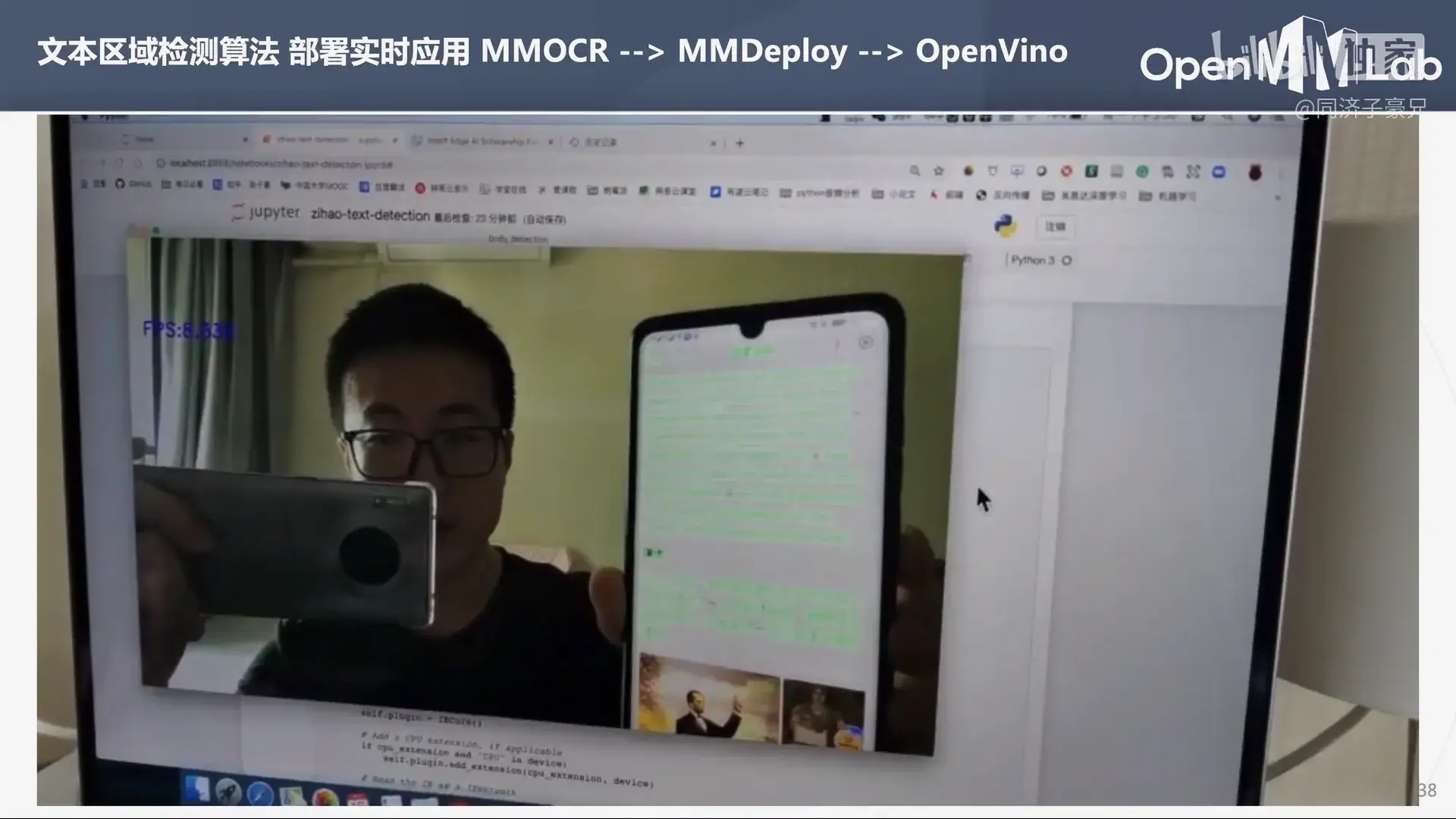
文本区域检测算法的部署,在 OpenVino 中实时调用摄像头进行场景文本检测。
常用 OCR 数据集和算法评估指标
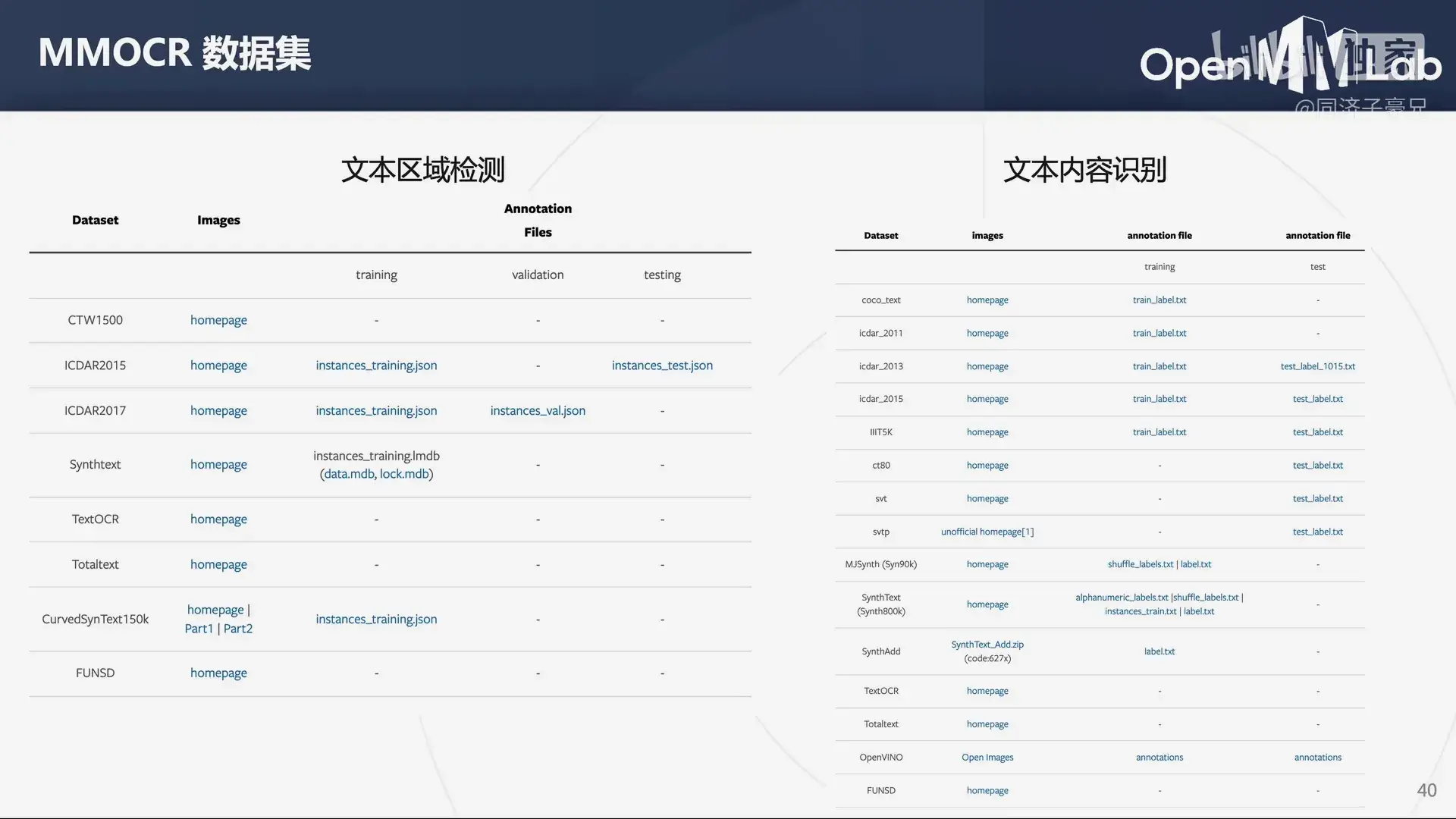
常用的文本检测和文本识别的数据集。
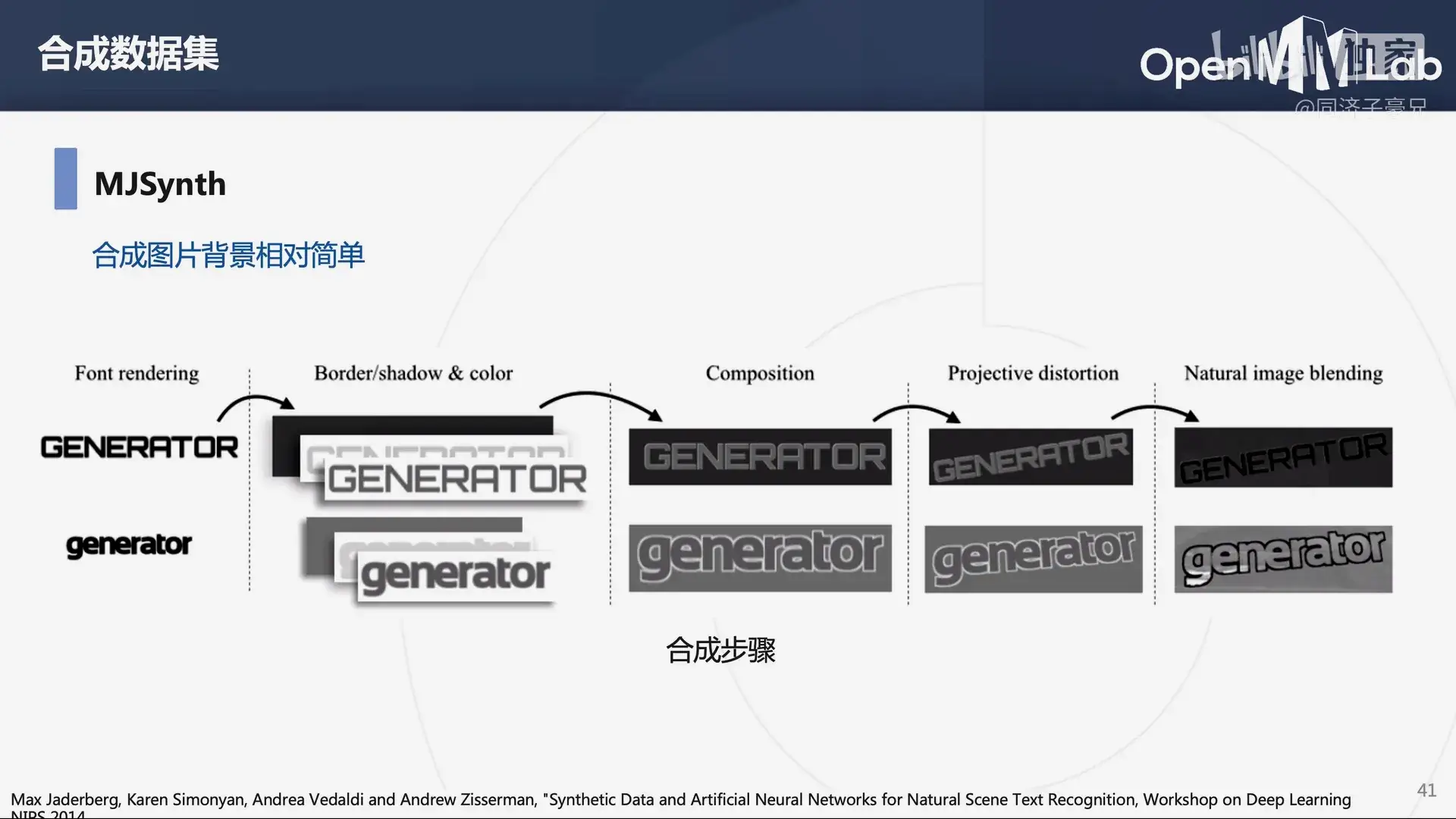
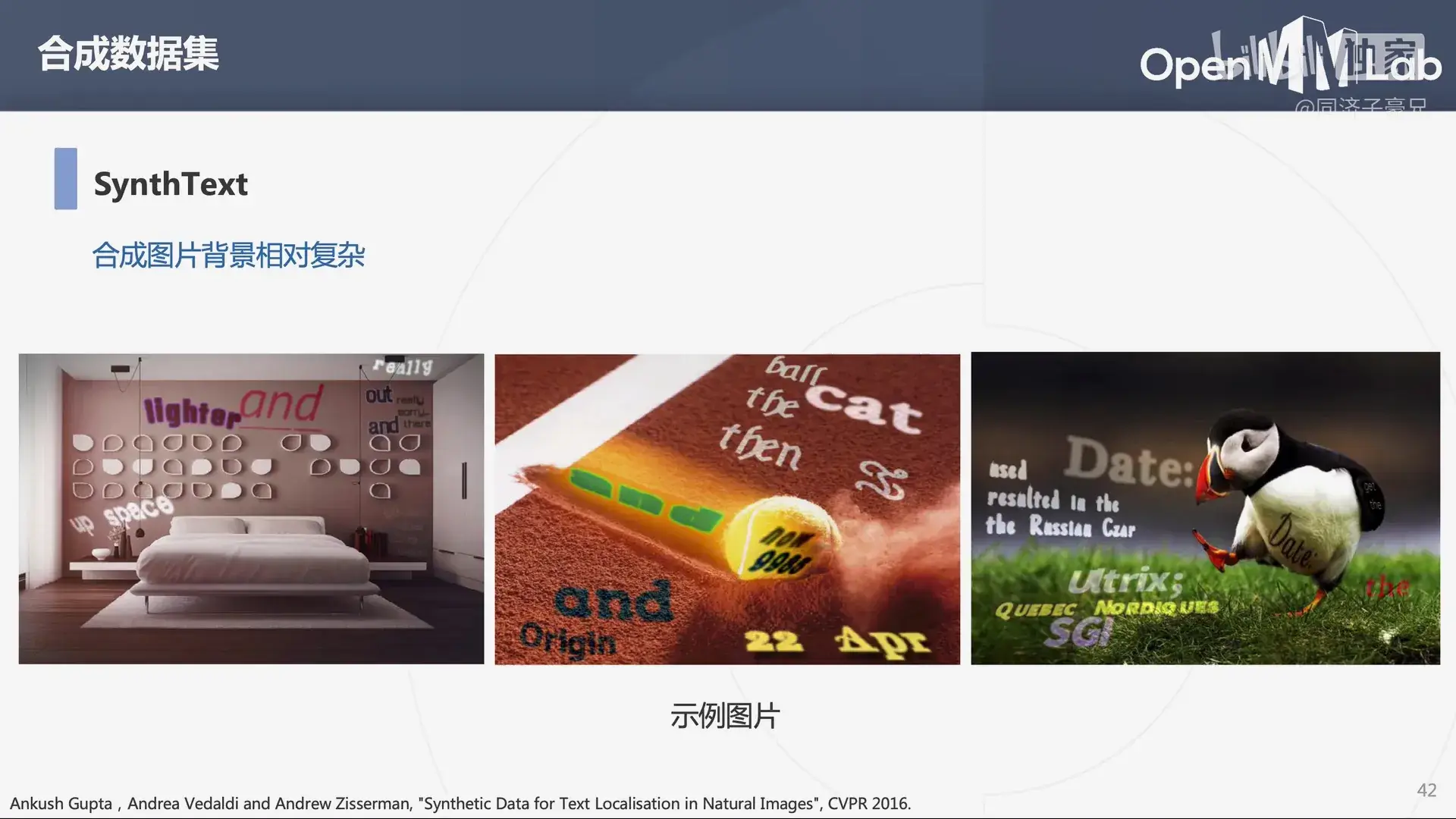
用于场景文本识别的数据集 MJSynth,合成图片背景相对简单。
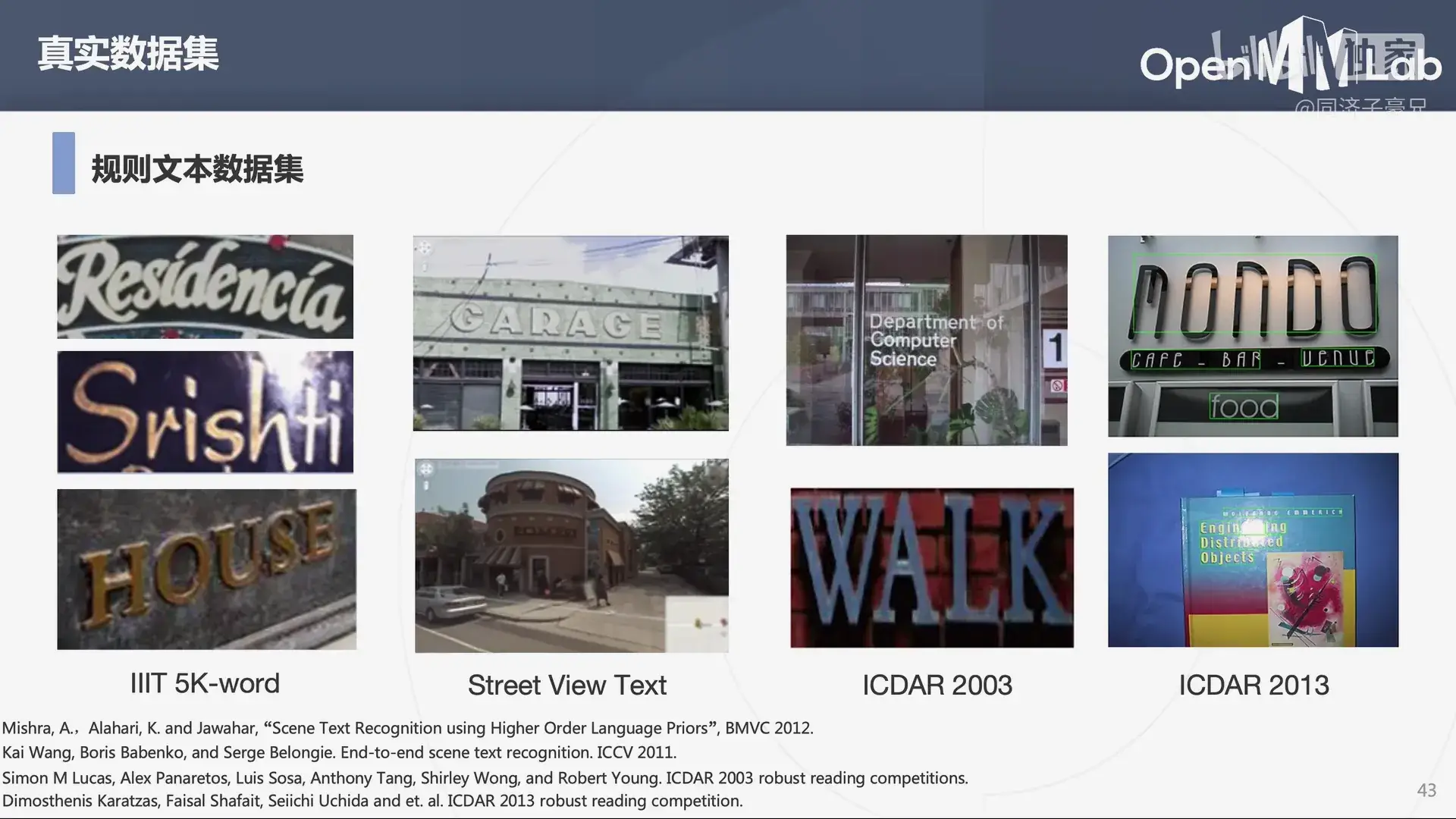
- Scene Text Recognition using Higher Order Language Priors - Inria - Institut national de recherche en sciences et technologies du numérique (hal.science)
- [1812.05824] ESIR: End-to-end Scene Text Recognition via Iterative Image Rectification (arxiv.org)
- (PDF) ICDAR 2003 robust reading competitions (researchgate.net)
- ICDAR 2013 Dataset | Papers With Code
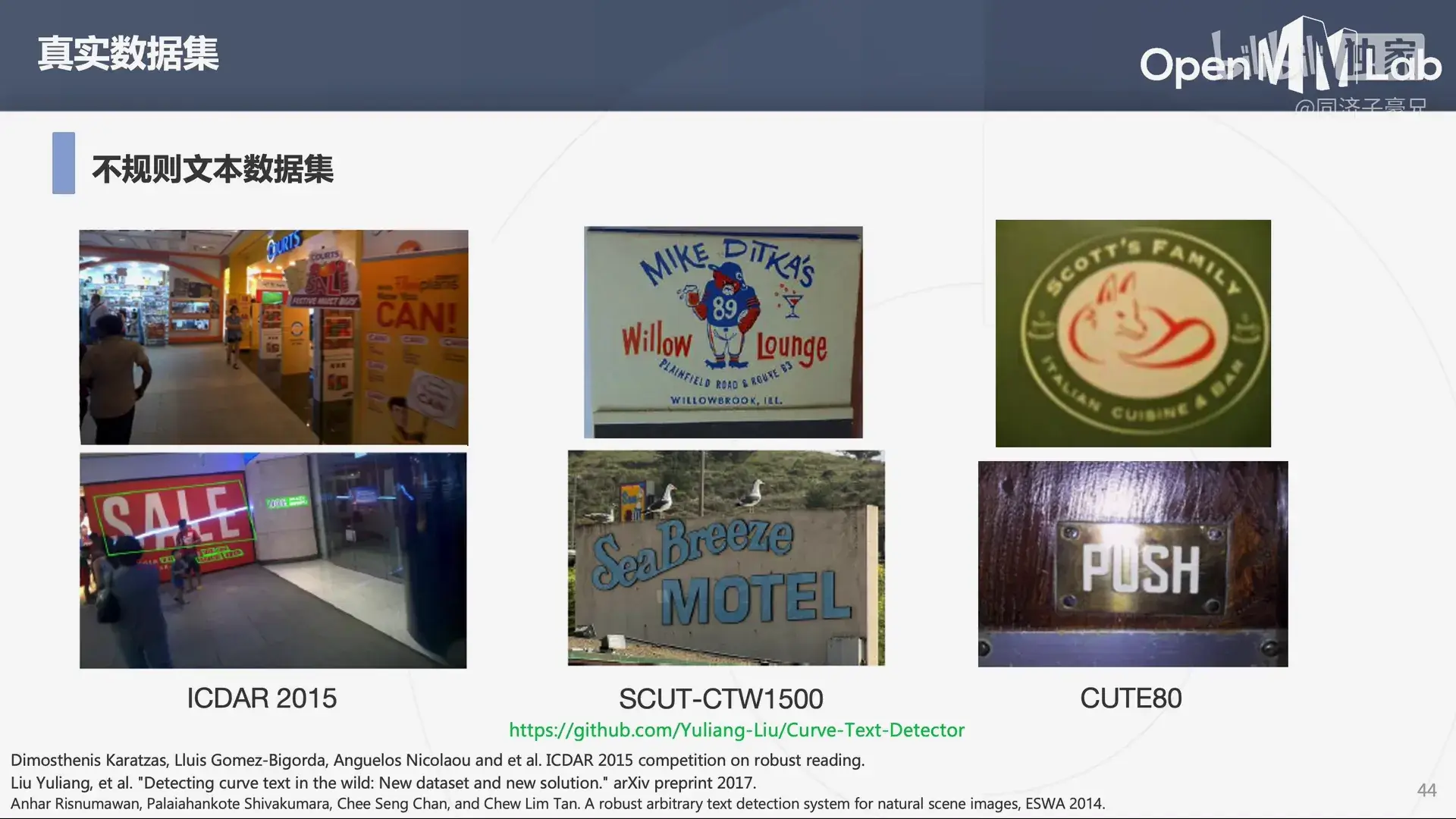
- ICDAR 2015 Dataset | Papers With Code
- SCUT-CTW1500 Dataset | Papers With Code
- SCUT-CTW1500 Dataset | Papers With Code

数据集由图像和标注两部分组成,对文本检测而言,它的标注范式与图像分割非常类似,都是用多段线去包络一个文字区域。
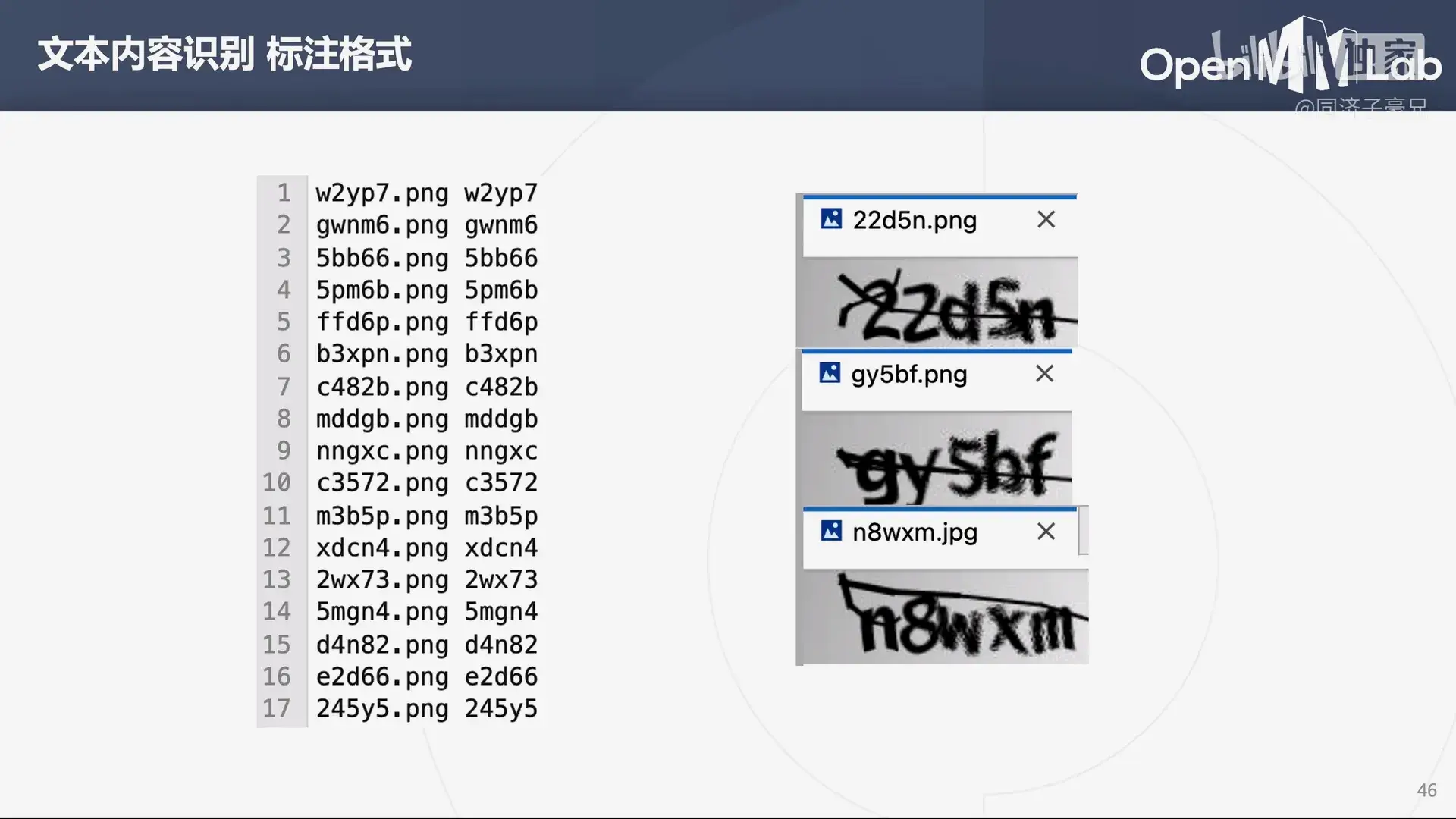
对于文本内容识别的任务,标注包含文件名和对应的文字内容。
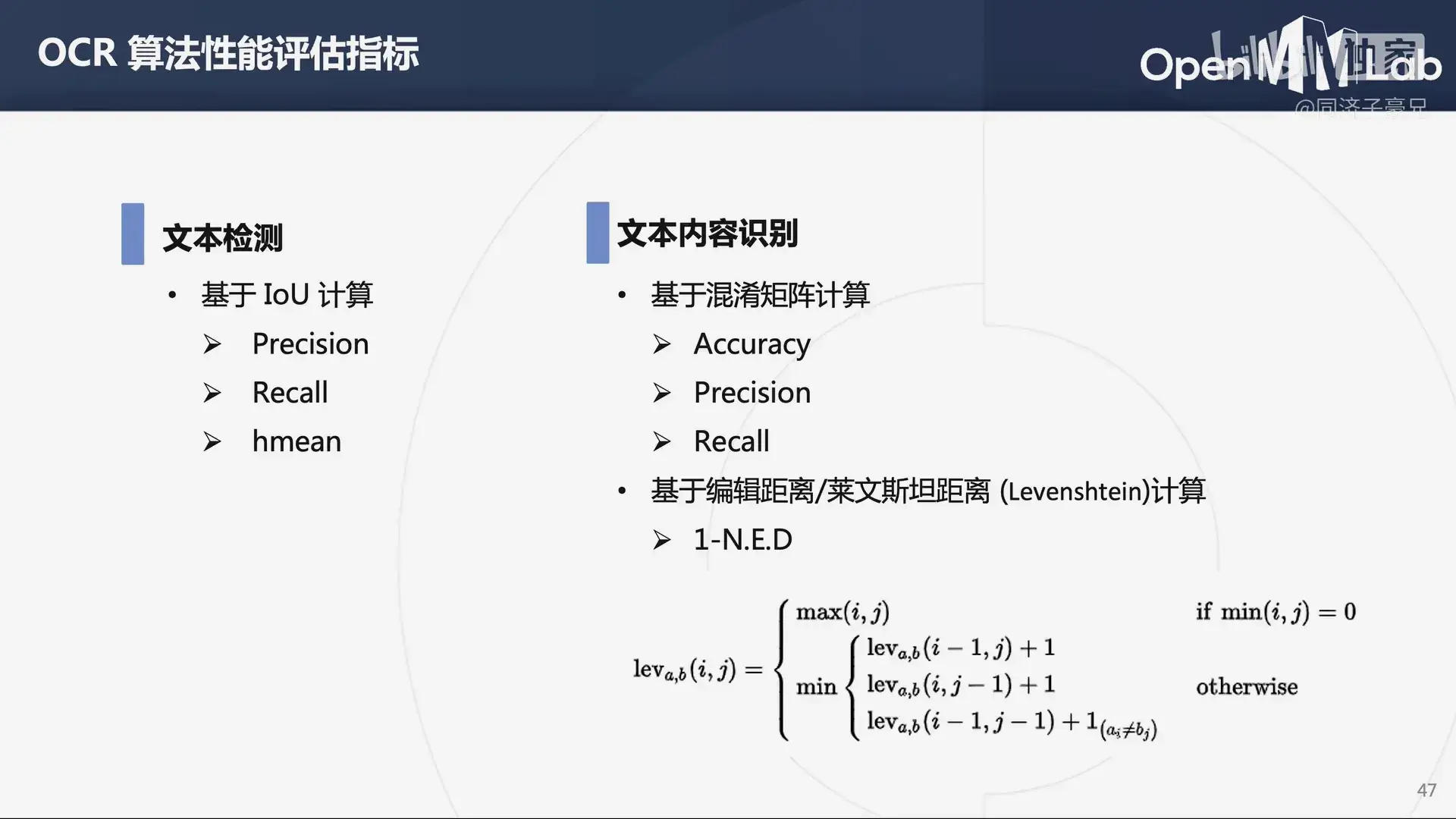
置信度(confidence) 模型在检测过程中,一个目标上可能会出现多个框,每一个框会对应一个 confidence,confidence 阈值就是之后计算 TP,FP,TN,FN 等参数的界限; 交并比(IOU) 计算模型预测出的框和标签中标注的框的 IOU,IOU 用于判定目标是真目标还是假目标,大于 IOU 阈值的框会认定为 True,小于 IOU 阈值的检测框会认定为 False; 计算 TP,FP,TN,FN
- TP:大于 IOU 阈值且大于 confidence 阈值(实际是正样本,判定为正样本);(检测对了)
- FP:小于 IOU 阈值且大于 confidence 阈值(实际是负样本,判定为正样本);(检测错了)
- TN:小于 IOU 阈值且小于 confidence 阈值(实际是负样本,判定为负样本);(不用于计算)
- FN:大于 IOU 阈值且小于 confidence 阈值(实际是正样本,判定为负样本);(没检测出来)
-
文本检测
- 基于 IoU 计算(预测区域和标记区域的交并集)
- Precision: TP / (TP + FP) 查准率
- Recall: TP / (TP + FN) 查全率,TP + FN 为所有正样本的数量
- hmean:P 与 R 的调和平均数
- 基于 IoU 计算(预测区域和标记区域的交并集)
-
文本内容识别
- 基于混淆矩阵计算(本质上是一个分类问题)
- Accuracy
- Precision
- Recall
- 基于编辑距离/莱文斯坦距离(Levenshtein)计算
- 1-N.E.D
- 基于混淆矩阵计算(本质上是一个分类问题)

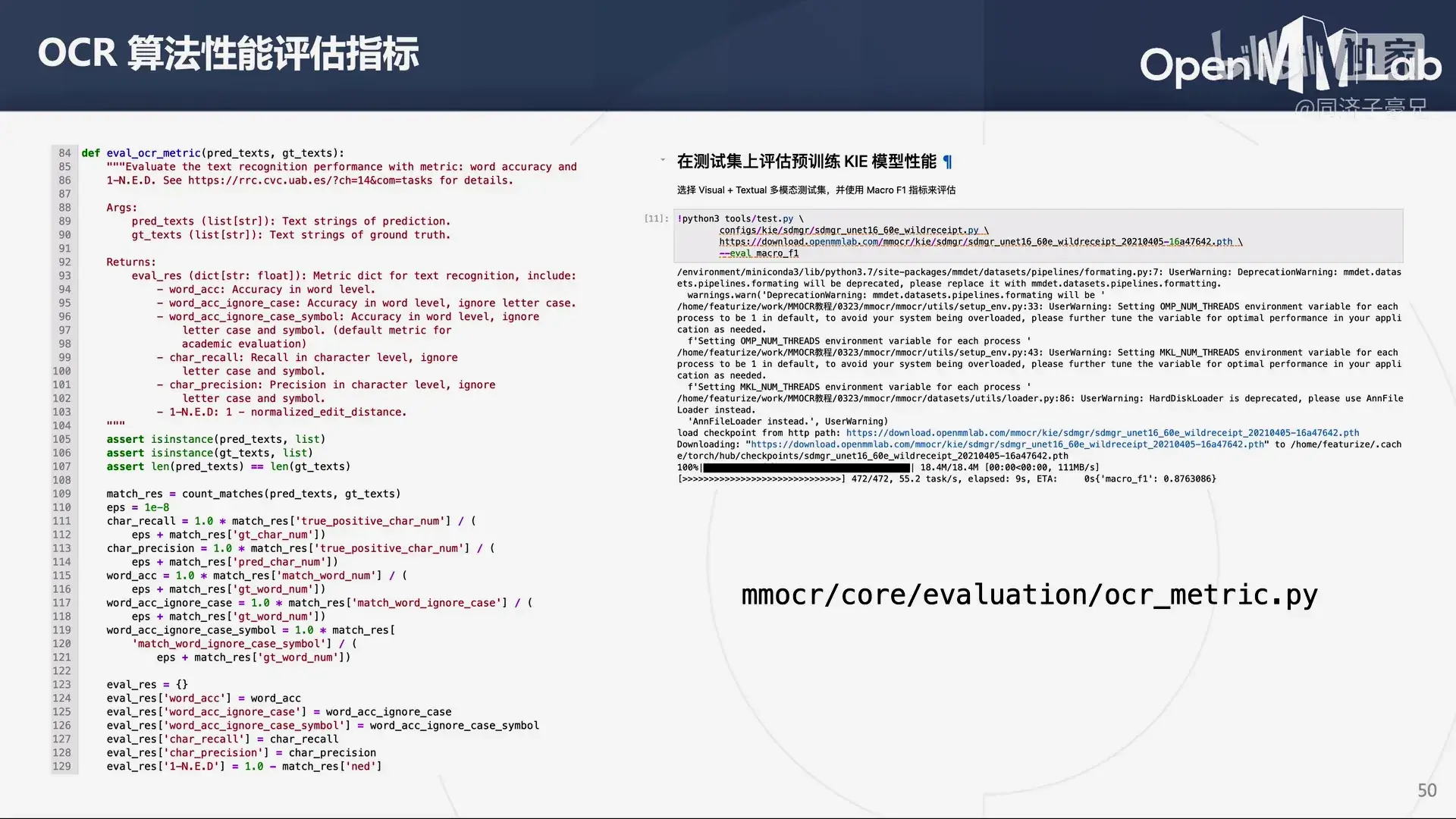
MMOCR 中集成了各种评估指标。
2
从 TommyZihao/MMOCR_tutorials: Jupyter notebook tutorials for MMOCR (github.com) 获取文件。
必须完成 A 才可以完成下面的内容!
A 安装配置 MMOCR
虚拟环境安装 jupyter notebook:在 conda 创建的虚拟环境中安装 jupyter 以及使用_conda 虚拟环境怎么连接 jupyter-CSDN 博客
安装 MMOCR:[Paper-MMOCR-A Comprehensive Toolbox for Text Detection, Recognition and Understanding | Zi-Zi's Journey](/2024/05/30/Paper-MMOCR-A Comprehensive Toolbox for Text Detection, Recognition and Understanding/)
检查安装成功:
# 检查 Pytorch
import torch, torchvision
print('Pytorch 版本', torch.__version__)
print('CUDA 是否可用',torch.cuda.is_available())Pytorch 版本 1.13.1+cu117
CUDA 是否可用 True
# 检查 mmcv
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print('MMCV 版本', mmcv.__version__)
print('CUDA 版本', get_compiling_cuda_version())
print('编译器版本', get_compiler_version())MMCV 版本 2.1.0
CUDA 版本 11.7
编译器版本 MSVC 192930148
# 检查 mmocr
import mmocr
print('mmocr 版本', mmocr.__version__)mmocr 版本 1.0.1
B1 预训练模型预测-文本识别
导入工具包:
from mmocr.apis import MMOCRInferencer
import cv2
import matplotlib.pyplot as plt
%matplotlib inline载入模型,实例化 MMOCRInferencer,rec='svtr-small' 使用 SVTR 模型进行文本识别:mmocr/configs/textrecog/svtr at main · open-mmlab/mmocr (github.com)。
下载 https://download.openmmlab.com/mmocr/textrecog/svtr/svtr-small_20e_st_mj/svtr-small_20e_st_mj-35d800d6.pth 并放到合适位置,使用 rec_weights 设定模型位置(如果没有设定,则它会自动下载到一个地方)
infer = MMOCRInferencer(rec='svtr-small', rec_weights='./models/svtr-small_20e_st_mj-35d800d6.pth')Loads checkpoint by local backend from path: ./models/svtr-small_20e_st_mj-35d800d6.pth
载入预测图像,就决定是你了:

场景文本识别模型只支持裁剪出文本区域的小图的识别。
img_path = './demo/ILoveGZ.png'
img_bgr = cv2.imread(img_path)
plt.imshow(img_bgr[:,:,::-1])
plt.show()
执行预测:
result = infer(img_path, save_vis=True, return_vis=True)解析预测结果-文本内容及置信度
result.keys()dict_keys(['predictions', 'visualization'])
result['predictions'][{'rec_texts': ['igz'], 'rec_scores': [0.9166250427563986]}]
解析预测结果-可视化:
plt.imshow(result['visualization'][0])
plt.show()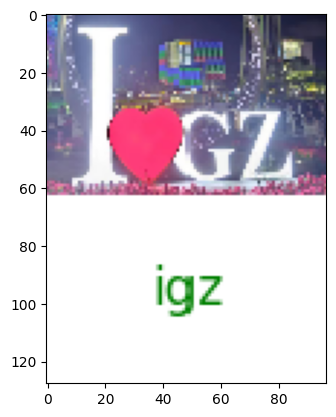
B2 预训练模型预测-文字区域检测
导入工具包:
from mmocr.apis import MMOCRInferencer
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline载入模型,实例化 MMOCRInferencer,det='textsnake' 使用 Textsnake 模型进行文本识别:[文本检测模型 — MMOCR 1.0.1 文档](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/svtr)。
下载 https://download.openmmlab.com/mmocr/textdet/textsnake/textsnake_resnet50-oclip_fpn-unet_1200e_ctw1500/textsnake_resnet50-oclip_fpn-unet_1200e_ctw1500_20221101_134814-a216e5b2.pth 并放到合适位置,使用 rec_weights 设定模型位置(如果没有设定,则它会自动下载到一个地方)
infer = MMOCRInferencer(det='textsnake', det_weights='./models/textsnake_resnet50-oclip_fpn-unet_1200e_ctw1500_20221101_134814-a216e5b2.pth')载入预测图像,就决定是你了:

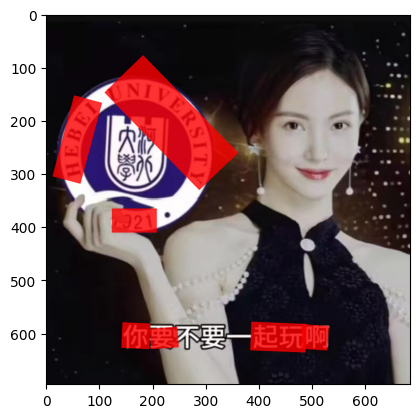
img_path = './demo/HBU.jpg'
img_bgr = cv2.imread(img_path)
plt.imshow(img_bgr[:,:,::-1])
plt.show()
执行预测:
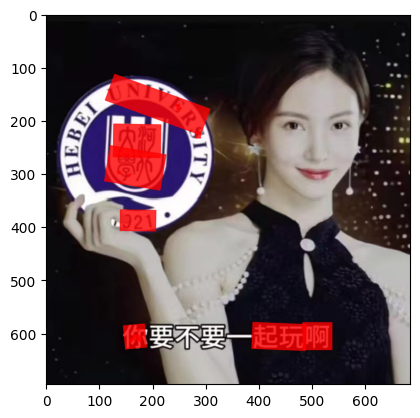
result = infer(img_path, return_vis=True)解析预测结果-文字区域及置信度:
result.keys()dict_keys(['predictions', 'visualization'])
解析预测结果-文字区域可视化:
plt.imshow(result['visualization'][0])
plt.show()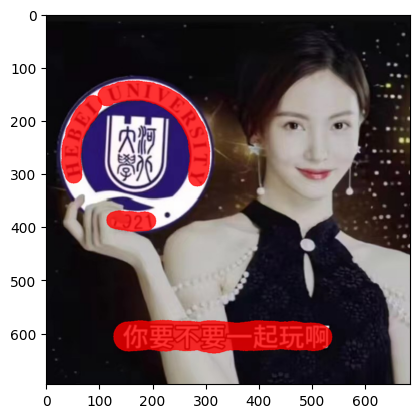
也可自行加载配置文件(Method)和对应的模型(Model):
从这里下载:文本检测模型 — MMOCR 1.0.1 文档
infer = MMOCRInferencer(det='./configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_totaltext.py', det_weights='./models/dbnet_resnet18_fpnc_1200e_totaltext-3ed3233c.pth')Loads checkpoint by local backend from path: ./models/dbnet_resnet18_fpnc_1200e_totaltext-3ed3233c.pth
预测结果虽然是长方形,但是似乎是检测到了弯曲文本,长方形是经过处理后得到的:
像如下模型:
infer = MMOCRInferencer(det='dbnet')Loads checkpoint by http backend from path: https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_resnet50-oclip_1200e_icdar2015/dbnet_resnet50-oclip_1200e_icdar2015_20221102_115917-bde8c87a.pth
对于弯曲文本,则检测失败:
B3 预训练模型预测-端到端 OCR
相当于对一张图片先进行场景文本检测,再进行场景文本识别。
导入工具包:
from mmocr.apis import MMOCRInferencer
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline载入场景文本检测模型:DBNet 以及场景文本识别模型:svtr-small:
infer = MMOCRInferencer(det='./configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_totaltext.py',
det_weights='./models/dbnet_resnet18_fpnc_1200e_totaltext-3ed3233c.pth',
rec='svtr-small')载入预测图像,就决定是你了:

img_path = './demo/TJ.jpg'
img_bgr = cv2.imread(img_path)
plt.imshow(img_bgr[:,:,::-1])
plt.show()
执行预测并获得结果:
result = infer(img_path, save_vis=True, return_vis=True)result['predictions'][{'rec_texts': ['scotland<UKN>s',
'cotland<UKN>s',
'scotland<UKN>s',
'cadenhead<UKN>s',
'cadenhead<UKN>s',
'cadenhead<UKN>s',
'cadenhead<UKN>s',
'shop',
'whisky',
'cadenhead',
'style<UKN>',
'<UKN>town',
'italian'],
'rec_scores': [0.977949458360672,
...
0.9994089433125087],
'det_polygons': [[759.0371750764526,
505.635521930197,
759.5478147298675,
494.91445790166443,
809.203618756371,
497.2781902810802,
808.6929791029562,
507.99925430961275],
...
[228.83700465086648,
339.75968070652175,
231.53506466615698,
289.6377231763757,
546.131936480632,
306.560987389606,
543.4338764653415,
356.6829250169837]],
'det_scores': [0.579411506652832,
...
0.8963190913200378]}]
得到了文本实例、文本范围以及相应的置信度。
可视化 OCR 结果(可以从 results/vis/ 文件夹下看到):

直接本地保存!
import numpy as np
from PIL import Image
Image.fromarray(result['visualization'][0]).save('output_image.png')B4 预训练模型预测-OCR 下游任务之 KIE
KIE 即 Key Information Extraction,旨在从图像(或文本)中提取出关键信息。这里 MMOCR 选用了一个 SDMGR 算法,用于发票信息提取。
一阵操作:
from mmocr.apis import MMOCRInferencer
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
infer = MMOCRInferencer(det='textsnake', rec='svtr-small', kie='SDMGR')
img_path = './demo/demo_kie.jpeg'
img_bgr = cv2.imread(img_path)
result = infer(img_path, save_vis=True, return_vis=True)
plt.imshow(result['visualization'][0])
plt.show()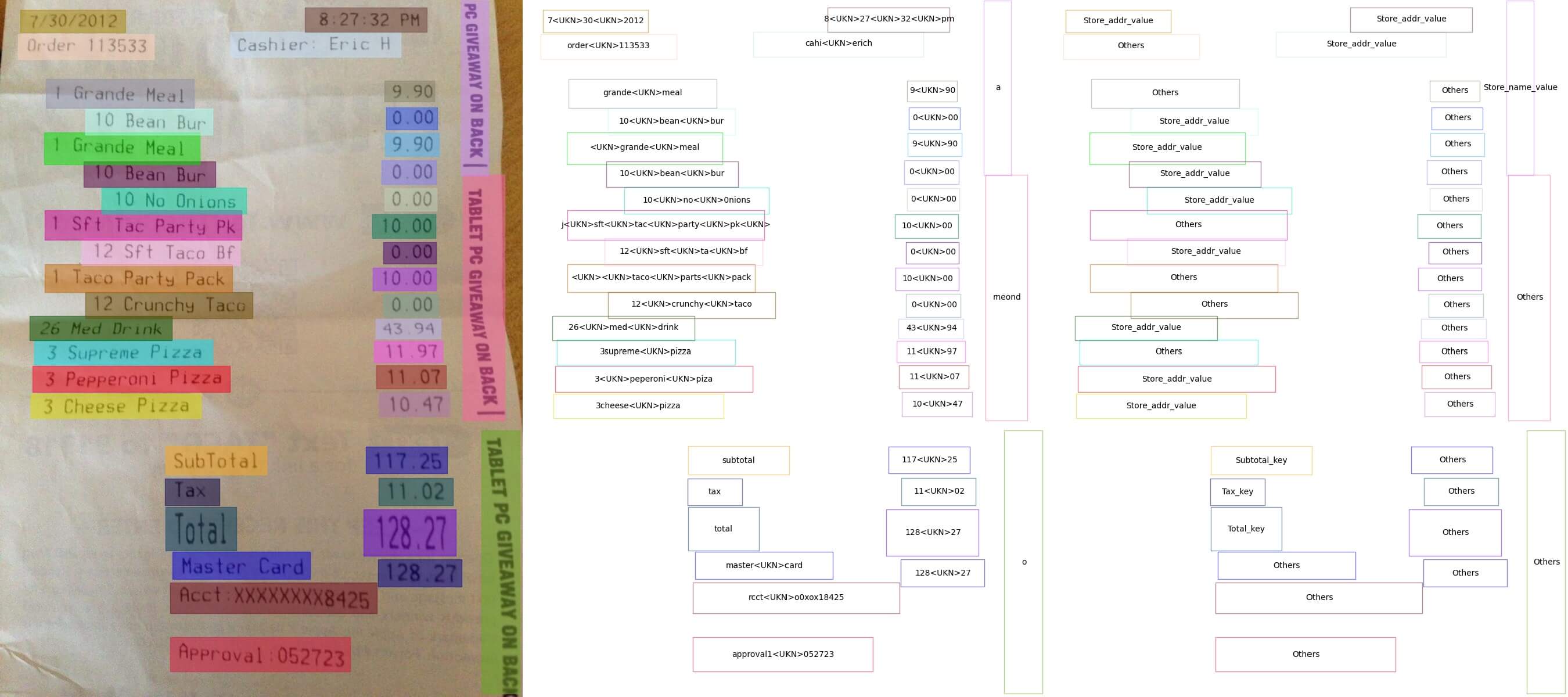
感觉这个算法就是将场景文本检测的结果出的框框再进行一个分类操作。
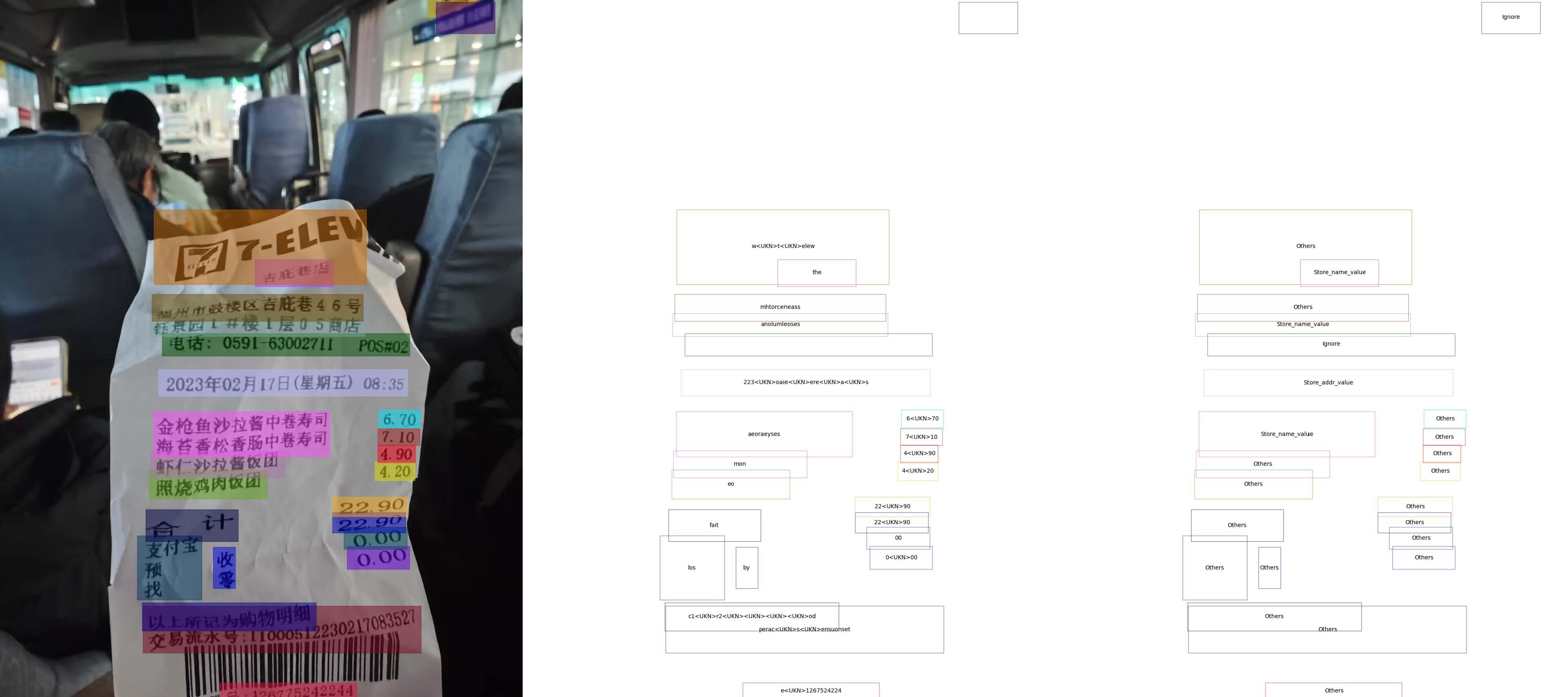
对自己的图片似乎也能识别出部分信息。
之后简单介绍了一下场景文本检测和场景文本识别的模型:



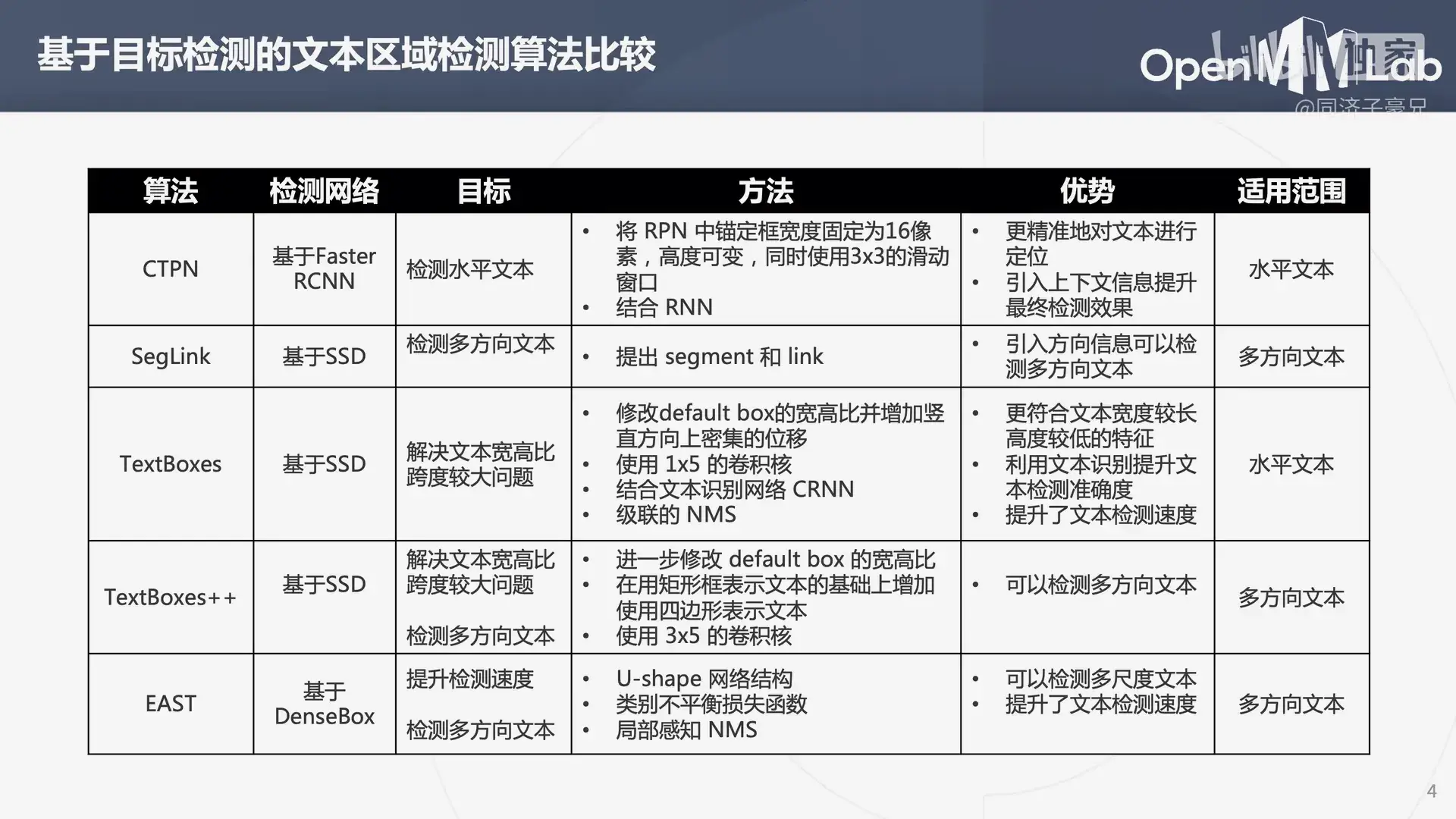
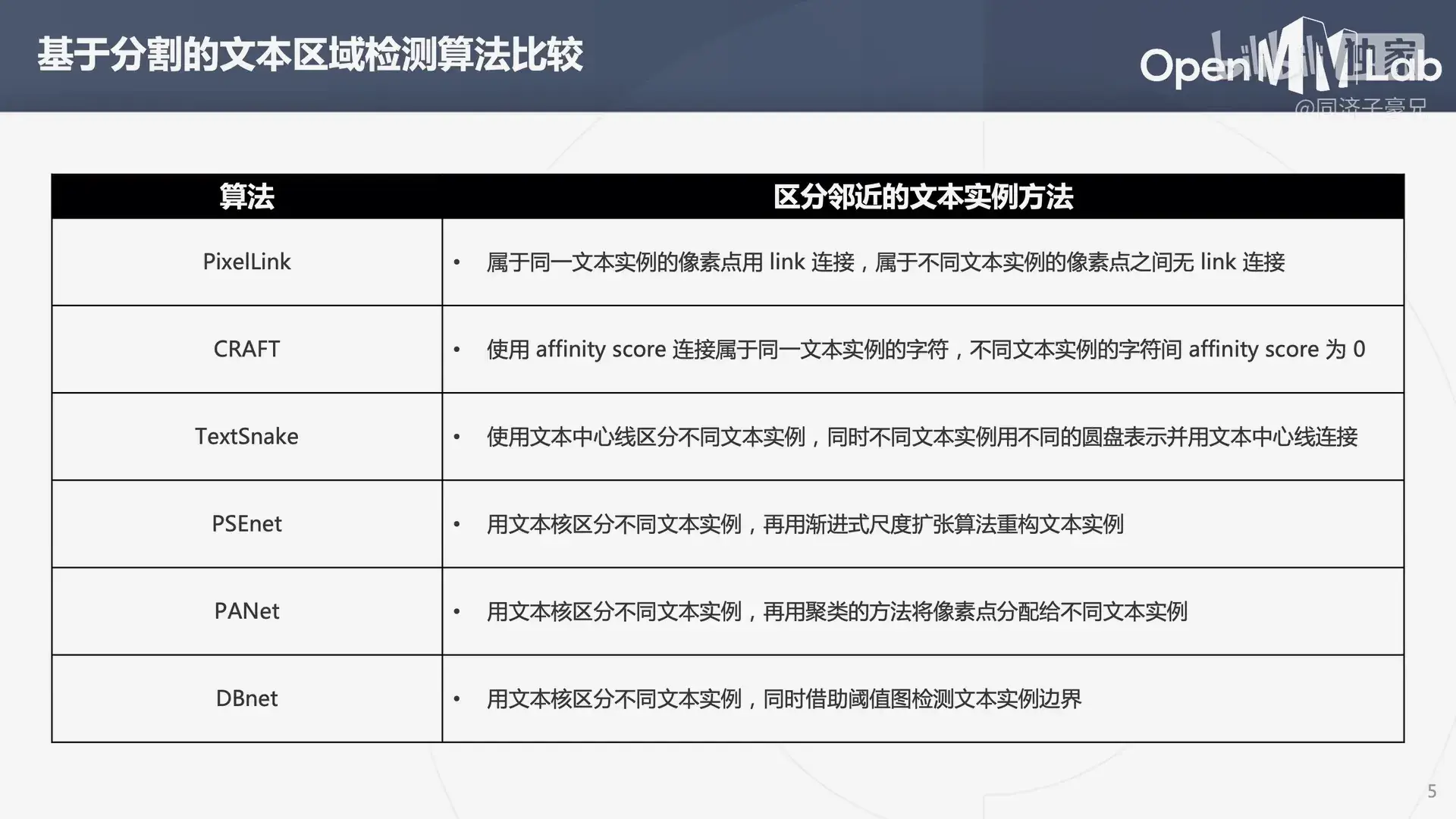

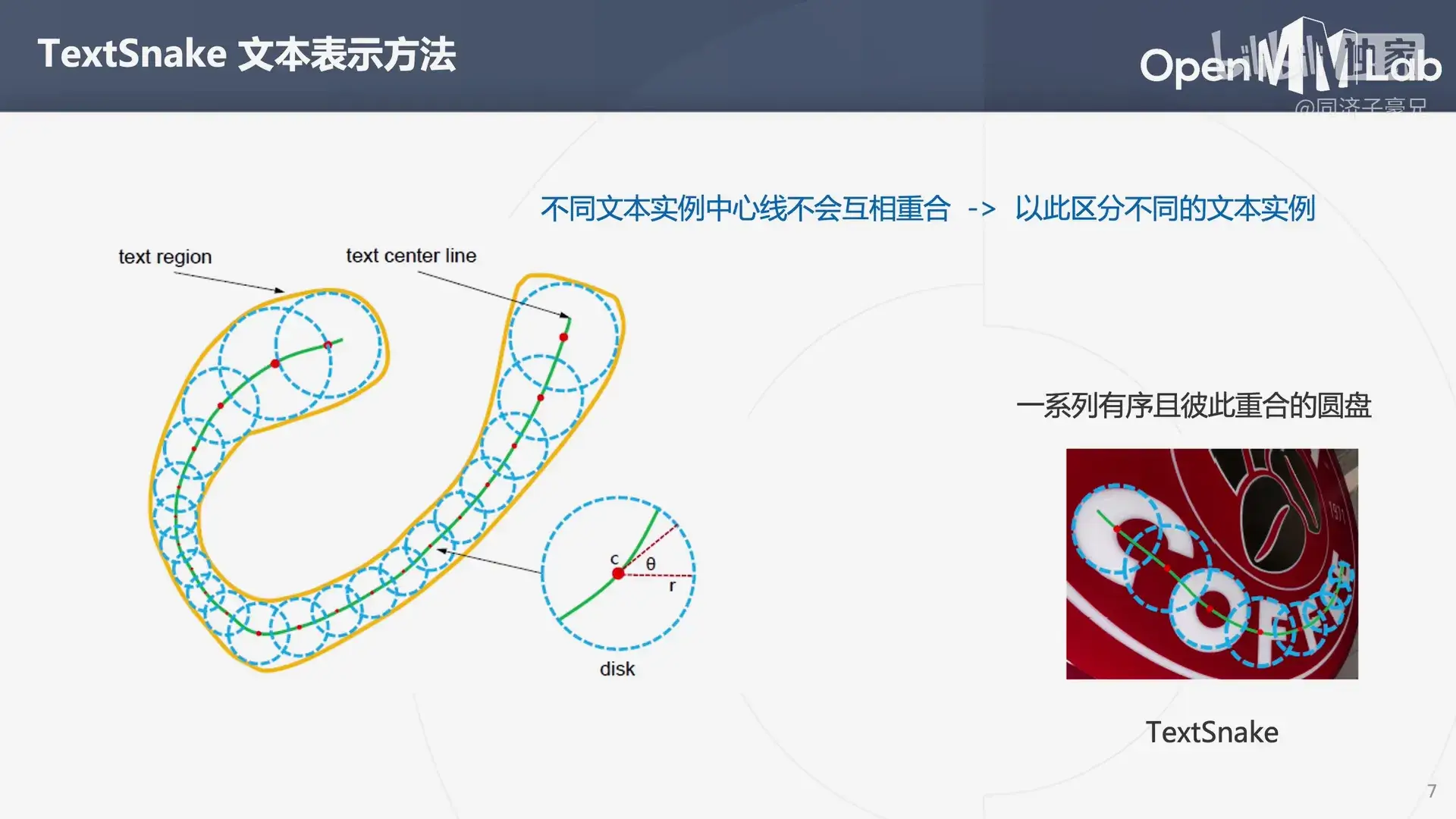
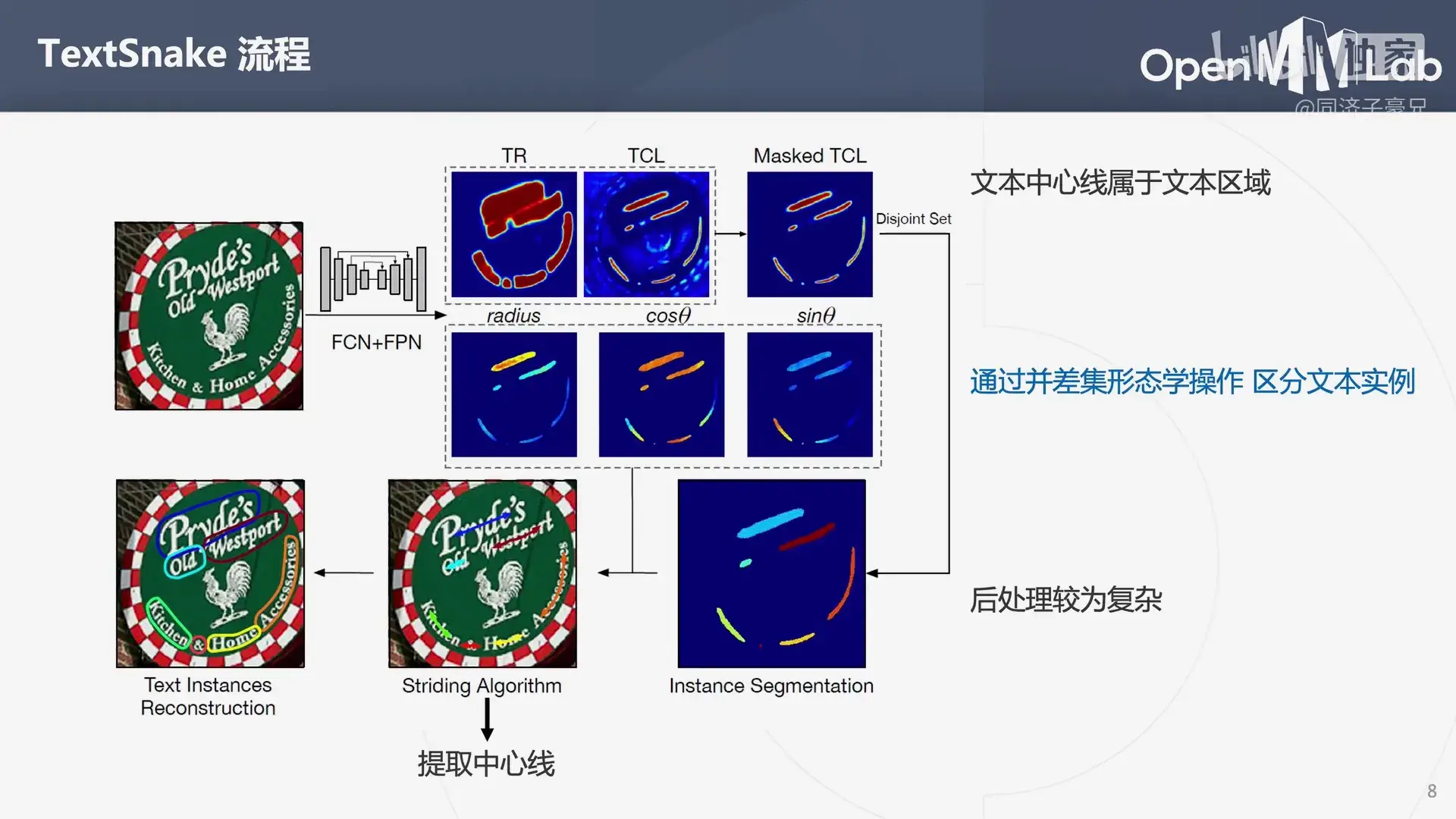
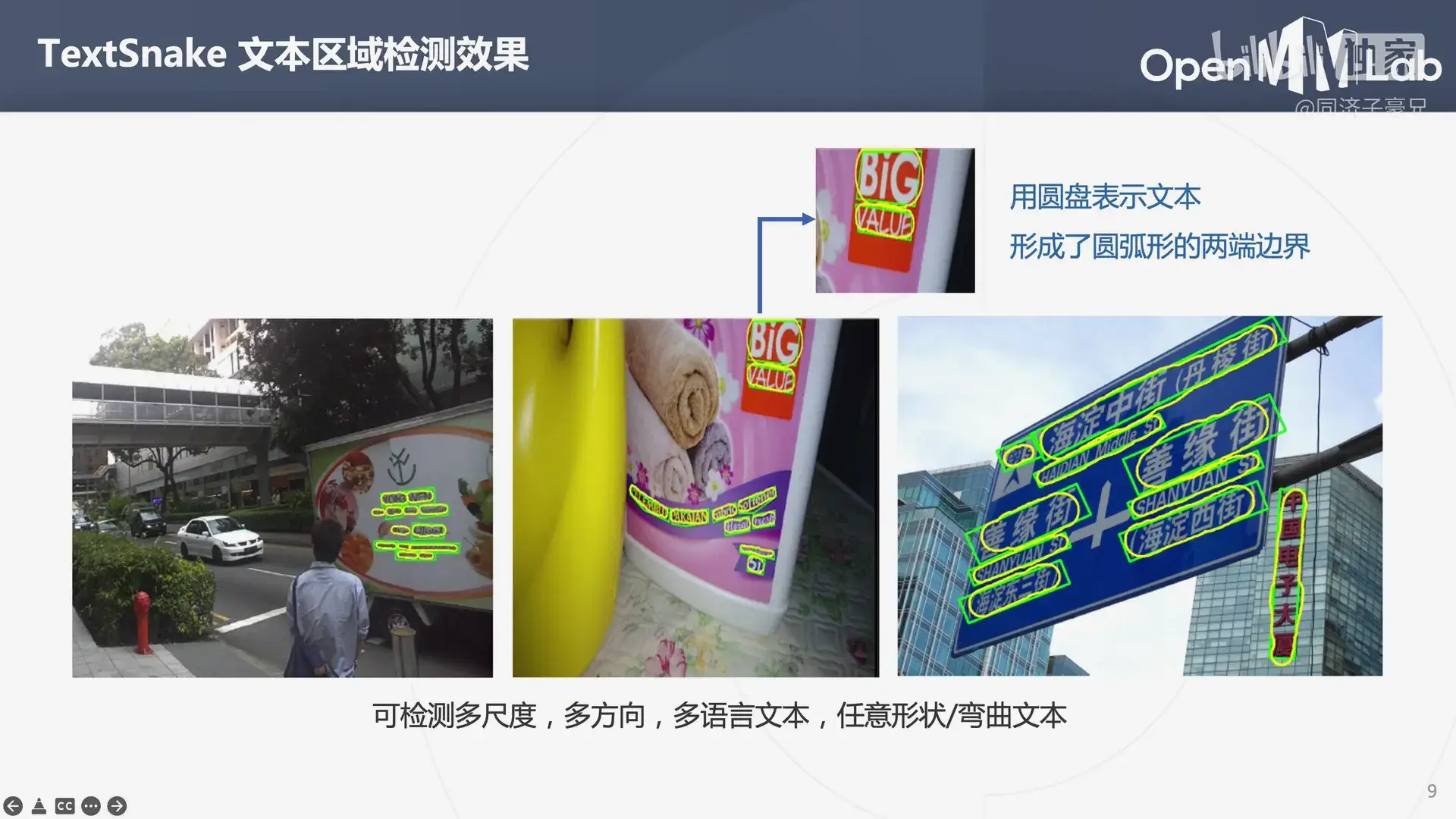






3
【C1】训练自己的文本识别模型
读取训练用的配置文件:
from mmengine import Config
cfg = Config.fromfile('./configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_totaltext.py')配置文件及解析:
这段 Python 代码主要用于配置文本检测模型的训练和测试管道,通常在深度学习框架(如 MMDetection 或类似项目)中使用。以下是对代码各部分的详细解释:
{% tabs config %}
_base_ = [
'_base_dbnet_resnet18_fpnc.py', # 基础模型配置文件
'../_base_/datasets/totaltext.py', # 数据集配置文件
'../_base_/default_runtime.py', # 默认运行时配置
'../_base_/schedules/schedule_sgd_1200e.py', # 学习率调度配置
]_base_列表包含几个基础配置文件的路径,这些文件定义了模型结构、数据集、运行时设置和训练计划等。
train_pipeline = [
dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
dict(
type='LoadOCRAnnotations',
with_polygon=True,
with_bbox=True,
with_label=True,
),
dict(type='FixInvalidPolygon', min_poly_points=4),
dict(
type='TorchVisionWrapper',
op='ColorJitter',
brightness=32.0 / 255,
saturation=0.5),
dict(
type='ImgAugWrapper',
args=[['Fliplr', 0.5],
dict(cls='Affine', rotate=[-10, 10]), ['Resize', [0.5, 3.0]]]),
dict(type='RandomCrop', min_side_ratio=0.1),
dict(type='Resize', scale=(640, 640), keep_ratio=True),
dict(type='Pad', size=(640, 640)),
dict(
type='PackTextDetInputs',
meta_keys=('img_path', 'ori_shape', 'img_shape'))
]-
train_pipeline定义了一系列处理步骤,用于训练数据的预处理:-
加载图像:从文件中读取图像,并忽略方向。
-
加载 OCR 注释:加载与文本检测相关的信息(多边形、边界框和标签)。
-
修复无效多边形:确保多边形至少包含 4 个顶点。
-
颜色抖动:随机调整图像的亮度和饱和度,增强训练数据的多样性。
-
图像增强:包括随机翻转、旋转和缩放。
-
随机裁剪:根据最小边比进行随机裁剪。
-
调整大小:将图像调整为 640 x 640 的大小,保持比例。
-
填充:如果图像小于 640 x 640,则填充至该尺寸。
-
打包输入:将处理后的图像和元数据打包成模型输入格式。
-
test_pipeline = [
dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
dict(type='Resize', scale=(1333, 736), keep_ratio=True),
dict(
type='LoadOCRAnnotations',
with_polygon=True,
with_bbox=True,
with_label=True,
),
dict(type='FixInvalidPolygon', min_poly_points=4),
dict(
type='PackTextDetInputs',
meta_keys=('img_path', 'ori_shape', 'img_shape', 'scale_factor'))
]-
test_pipeline与train_pipeline类似,但针对测试阶段进行了调整:-
图像被调整为 1333 x 736 的大小。
-
同样加载 OCR 注释并修复无效多边形。
-
# dataset settings
totaltext_textdet_train = _base_.totaltext_textdet_train
totaltext_textdet_test = _base_.totaltext_textdet_test
totaltext_textdet_train.pipeline = train_pipeline
totaltext_textdet_test.pipeline = test_pipeline- 从基础配置中获取训练和测试数据集,并为它们指定相应的处理管道。
train_dataloader = dict(
batch_size=16,
num_workers=16,
pin_memory=True,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=totaltext_textdet_train)
val_dataloader = dict(
batch_size=1,
num_workers=1,
pin_memory=True,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=totaltext_textdet_test)
test_dataloader = val_dataloader-
train_dataloader和val_dataloader定义了训练和验证的数据加载器:-
batch_size:每个批次的样本数量(训练为 16,验证为 1)。
-
num_workers:用于数据加载的工作线程数。
-
pin_memory:是否将数据加载到固定内存中,以加快 GPU 训练。
-
persistent_workers:在数据加载过程中保持工作线程持续运行。
-
sampler:数据的采样方式(训练时打乱顺序,验证时不打乱)。
-
auto_scale_lr = dict(base_batch_size=16)- 配置自动缩放学习率的选项,以便根据基础批次大小动态调整学习率。
{% endtabs %}
转换为 onnx
从 open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework 下载 MMDeploy 的源代码。
继续安装库:
pip install mmdeploy
pip install onnx==1.16.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple 执行转换命令:
python tools/deploy.py configs/mmocr/text-detection/text-detection_onnxruntime_dynamic.py D:/XXX/MMOCR/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_totaltext.py D:/XXX/MMOCR/models/dbnet_resnet18_fpnc_1200e_totaltext-3ed3233c.pth demo/resources/text_det.jpg --work-dir mmdeploy_models/mmocr/dbnet/ort --device cpu --show --dump-info得到对应的 onnx 模型 mmdeploy_models/mmocr/dbnet/ort/end2end.onnx。
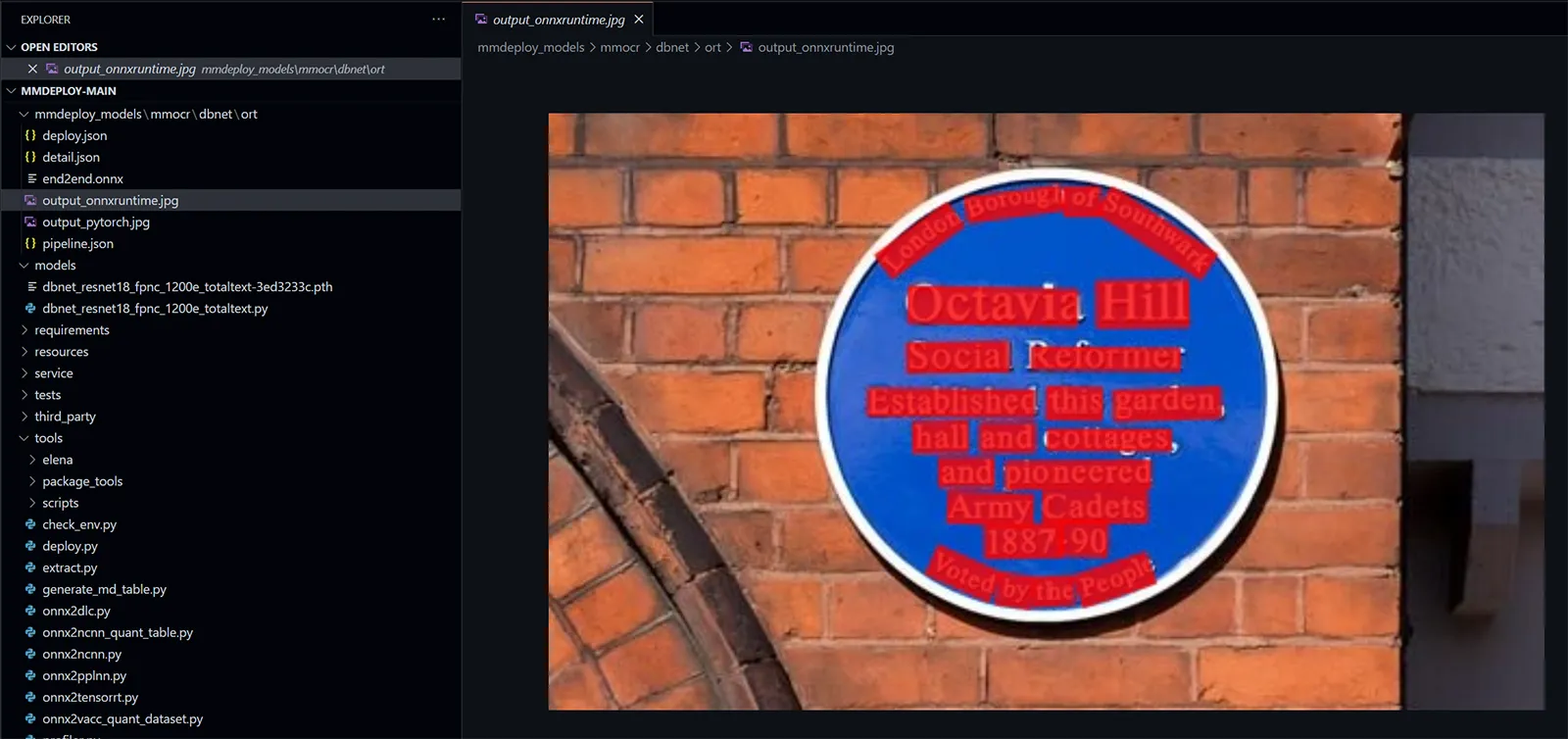
下面的代码用于使用这个 onnx 模型:
import onnxruntime as ort
import cv2
import numpy as np
import matplotlib.pyplot as plt
import numpy as np
# 加载 ONNX 模型
onnx_model_path = "mmdeploy_models/mmocr/dbnet/ort/end2end.onnx"
session = ort.InferenceSession(onnx_model_path, providers=['CPUExecutionProvider'])
# 加载并预处理输入图像
image_path = "demo/resources/promefire.jpg"
image = cv2.imread(image_path)
# 图像预处理函数
def preprocess(image, input_shape):
# 为动态输入形状指定默认值
height = 640 # 模型的默认高度
width = 640 # 模型的默认宽度
# 调整大小并归一化
resized = cv2.resize(image, (width, height))
normalized = resized / 255.0
input_tensor = np.transpose(normalized, (2, 0, 1)) # HWC -> CHW
input_tensor = np.expand_dims(input_tensor, axis=0).astype(np.float32) # 增加 Batch 维度
return input_tensor
# 获取模型输入形状
input_name = session.get_inputs()[0].name
input_shape = session.get_inputs()[0].shape
# 打印输入形状用于调试
print("Input shape from model:", input_shape)
# 预处理图像
input_tensor = preprocess(image, input_shape)
# 推理
outputs = session.run(None, {input_name: input_tensor})
# 处理输出
output_name = session.get_outputs()[0].name
output_data = outputs[0]
# 打印模型输出
print("模型输出:", output_data)
# 假设 output_data 是你的模型输出
output_data = outputs[0][0] # 去除 batch 维度,得到二维数组
# 绘制热力图
plt.imshow(output_data, cmap='hot', interpolation='nearest')
plt.colorbar() # 添加颜色条
plt.title("Text Detection Heatmap")
plt.show()
# 阈值化
threshold = 0.5
binary_map = (output_data > threshold).astype(np.uint8) * 255 # 转为二值图像 (0 或 255)
# 保存和显示二值图像
cv2.imwrite("binary_output.png", binary_map)
cv2.imshow("Binary Map", binary_map)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 加载原始图像
original_image = cv2.imread(image_path)
original_image = cv2.resize(original_image, (output_data.shape[1], output_data.shape[0]))
# 叠加热力图
heatmap = cv2.applyColorMap((output_data * 255).astype(np.uint8), cv2.COLORMAP_JET)
overlay = cv2.addWeighted(original_image, 0.6, heatmap, 0.4, 0) # 叠加效果
# 显示叠加图像
cv2.imshow("Overlay", overlay)
cv2.waitKey(0)
cv2.destroyAllWindows()